

Wer, wie, was: Textanalyse über Natural Language Processing mit BERT
Seite 3: Transfer Learning mit BERT
Diese Nachteile versucht BERT (Bidirectional Encoder Representations from Transformers) zu umgehen. Die ursprüngliche Idee stammt von Google. Mit weiteren Verbesserungen ist inzwischen ein umfangreiches Ökosystem dazu entstanden.

Die Grundidee von BERT ist das sogenannte Transfer Learning. Data Scientists trainieren zunächst ein Sprachmodell ähnlich wie bei ELMo auf einem großen Korpus. Anders als bei ELMo können sie die erzielten Erkenntnisse in Form von Modellen weiterverwenden. Dafür müssen sie sie allerdings mit dem sogenannten Finetuning anpassen. Damit ist der Rechenaufwand immer noch groß, aber im Vergleich zum Gesamtmodell durchaus auf moderater Hardware in überschaubarer Zeit zu bewältigen.
Auslassen als Trainingshilfe
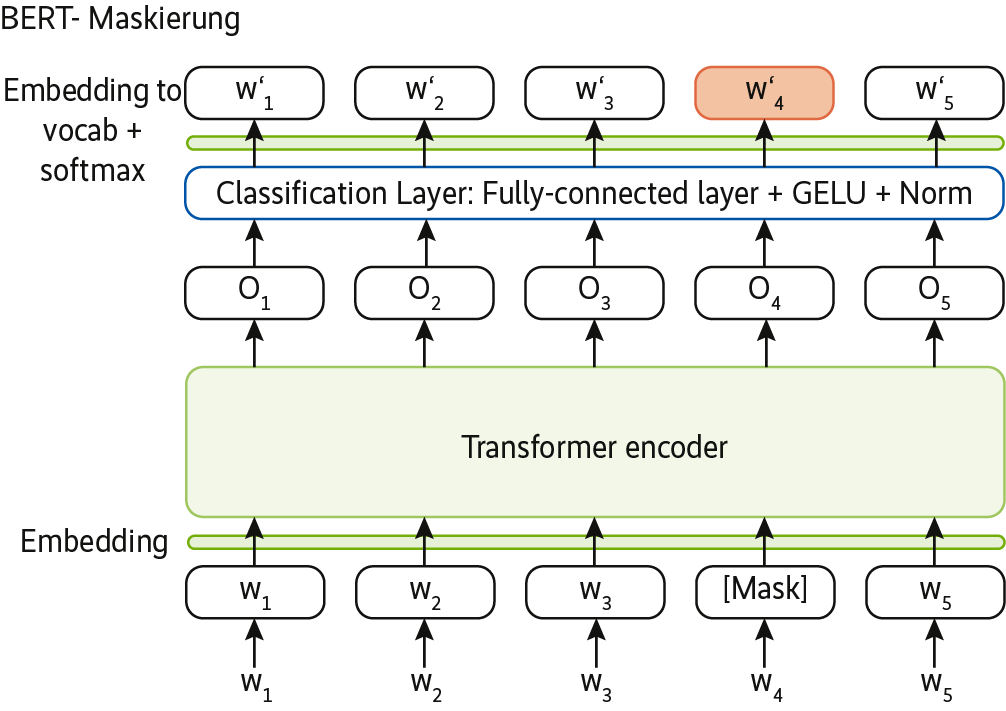
Ein Trick hilft dabei, das Modell besser trainieren zu können und es gegenüber Störungen zu immunisieren: Bestimmte Wörter werden absichtlich weggelassen, und das System dazu in einer Weise trainiert, dass es sie wieder vorhersagen kann.
(Bild: Towards Data Science)
Für BERT verwenden Data Scientists ein mehrschichtiges tiefes neuronales Netz (DNN, Deep Neural Network) mit üblicherweise zwölf Layers, das sie darauf trainieren, den jeweils nächsten Satz vorherzusagen. Ein Beispiel auf der Webseite towards data science verdeutlicht das Vorgehen (s. Abb. 10).
![Einsatz von BERT zur Klassifikation, wofür alleine der vollkontextualisierte Wortvektor von [CLS] genutzt wid (Abb. 11)](/imgs/18/2/9/4/7/9/8/9/Grafik11-b54a08fefd5db905.png)
Entscheidend sind dabei die Tokens, die den Anfang [CLS] und das Ende [SEP] eines Satzes markieren. Durch die komplette Kontextualisierung können sie abhängig von ihrem Kontext die gesamte Bedeutung des Satzes darstellen. Diese Tatsache lässt sich für das Finetuning verwenden.
BERT in der Praxis
Glücklicherweise muss sich niemand mit allen Details von BERT auseinandersetzen, um es nutzen zu können. Google stellt mehrere vortrainierte Modelle zur Verfügung, die das folgende Codebeispiel nutzt. Das Training der Modelle hat äußerst lange gedauert: Ganze Rechenzentren von Google mit hochspezialisierten TPUs (Tensor Processing Units) waren damit viele Tage beschäftigt. Für Unternehmen, die das Modell nur nutzen wollen, wären damit große Investitionen in Rechner oder Rechenleistung erforderlich, die durch die vorgefertigten und übertragbaren Modelle deutlich geringer ausfallen.
Google hat BERT ursprünglich in TensorFlow implementiert. Die seinerzeit kleine Firma Huggingface hat auf der Grundlage ein deutlich eleganteres Interface geschaffen, dessen PyTorch-API im Folgenden zum Einsatz kommt.
Das Colab-Notebook berechnet mit BERT die Embeddings der Heise-Headlines von 2019 und bestimmt die ähnlichsten (s. Abb. 12). Dabei hilft, dass der vorletzte BERT-Layer die gewünschten Embeddings enthält, die sich mit PyTorch auslesen lassen.

Finetuning zur Klassifikation
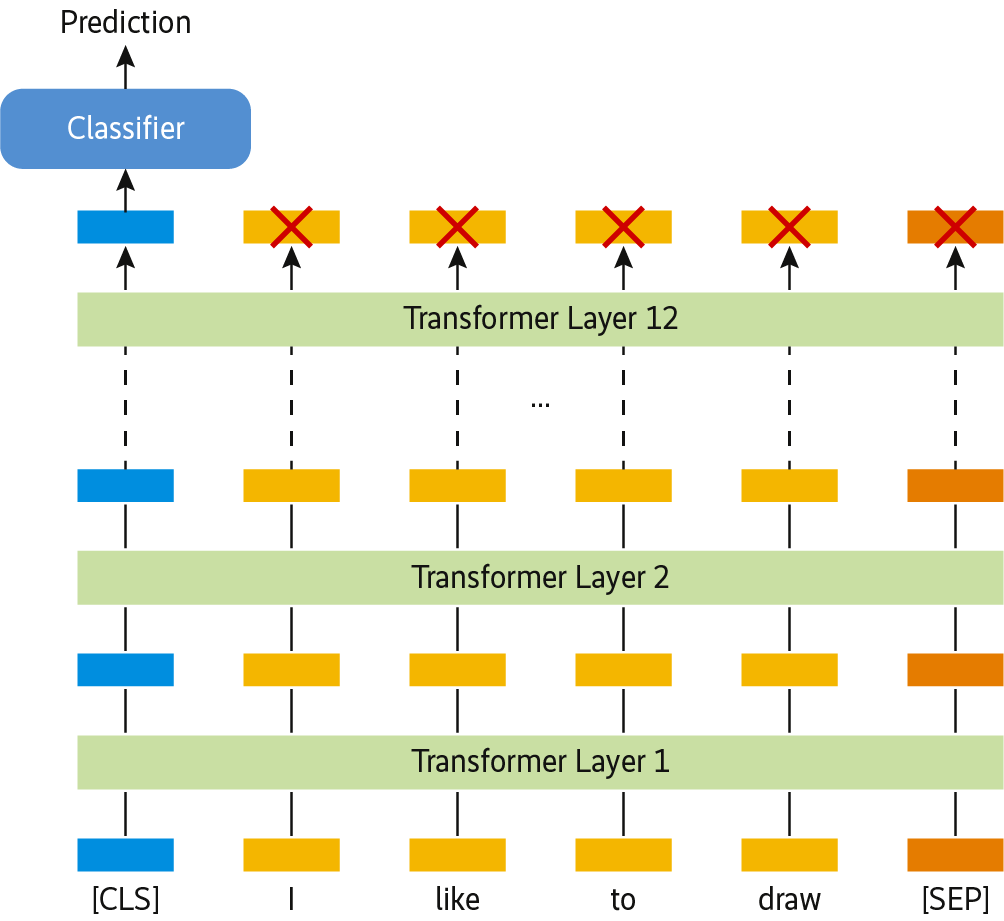
Die wahre Stärke von BERT ist allerdings nicht das Berechnen kontextualisierter Embeddings, sondern deren Nutzung, um beispielsweise Klassifikationsprobleme zu lösen. Die Idee dahinter ist, lediglich den (kontextualisierten) Wortvektor des jeweiligen Satzanfangs ([CLS]-Token) zu berücksichtigen und nur im letzten Layer die Gewichte auf eine Weise anzupassen, die ein Einordnen des Satzes in die passende Kategorie ermöglicht (s. Abb. 13).
(Bild: Chris McCormick)
Besonders gut geeignet ist das Vorgehen für Aufgabenstellungen wie Sentiment-Analyse, in denen es auf die Semantik der Sätze ankommt. Für den Heise-Newsticker ließe sich das System unter anderem effektiv einsetzen, um Troll-Kommentare zu erkennen. Der folgende Code versucht, mit BERT vorherzusagen, welche Headlines besonders viele Kommentare auf sich ziehen. Dazu ist der komplette Datensatz in solche mit wenigen (<20) und solche mit vielen Kommentaren (>100) unterteilt:

Das in Machine-Learning-Szenarien übliche und wichtige Vorgehen, mit einem Trainings- und Testdatensatz zu arbeiten, entfällt im Beispiel, um den Code nicht unnötig aufzublähen. Trotz des fehlenden Abgleichs ist die Klassifikationsperformance recht gut.
Question Answering
Statt BERT auf die Heise-Headlines zu tunen, lässt es sich auf andere Anforderungen optimieren. Besonders populär und beeindruckend ist dabei das sogenannte Question Answering.
Data Scientists starten mit einem trainierten Sprachmodell, das sie mit einem sogenannten Squad-Korpus feintunen, bei dem sie als Trainigsmenge viele Texte mit den dazugehörigen Fragen zur Verfügung stellen. Das jeweilige Vorhersageergebnis ist die Antwort auf die Frage, die im Text vorhanden sein sollte. Das Modell wird auf diese Fragen-Antworte-Paare trainiert.
Was unglaublich klingt, lässt sich in der Praxis gut einsetzen und produziert gespenstisch gute Resultate. 2019 gelang es einem Forscherteam, ein System zu trainieren, das den amerikanischen Schulabschluss der zehnten Klasse mit 80 Prozent Score bestehen kann. Dabei handelt es sich zwar um einen Multiple-Choice-Test, aber eine gute Zahl von Schülern bestehen den Test nicht.
Das Experiment im Rahmen dieses Artikels ist etwas bescheidener: Ein Bot soll ein paar Fragen zum Wikipedia-Artikel über Raumschiff Enterprise beantworten. Lustig ist am Rande, wie wenig tief das Verständnis des Systems tatsächlich ist, wenn es auf Fragen antwortet, deren Antwort sich im Text nicht findet

