

Datamining beim Bilderdienst
Eine Studie kanadischer Forscher zeigt, wie einfach sich Rückschlüsse aus Social-Networking-Daten ziehen lassen.
- Kentucky FC
Eine Studie kanadischer Forscher zeigt, wie einfach sich Rückschlüsse aus Social-Networking-Daten ziehen lassen.
Wer soziale Netzwerke nutzt, muss damit rechnen, dass schon die dabei entstehende Datenstruktur viel über die eigene Persönlichkeit verrät – und zwar ohne direkten Zugriff auf Profilinformationen. Forscher an der University of Victoria im kanadischen Bundesstaat British Columbia haben nun anhand von Geodaten beim Bilderdienst Flickr dokumentiert, wie einfach sich Rückschlüsse auf den Heimatort eines Nutzers ziehen lassen.
Geodaten stecken in immer mehr digitalen Bildern: Sie werden über den GPS-Chip in Kamera oder Smartphone in eine Aufnahme integriert. Zwar machen Nutzer von ihrem Heimatort normalerweise besonders viele Fotos. Doch allein aus der Bildmenge lässt sich die Herkunft noch nicht festlegen – schließlich knipsen Nutzer etwa an einem Urlaubsort ebenfalls oft zahlreiche Bilder.
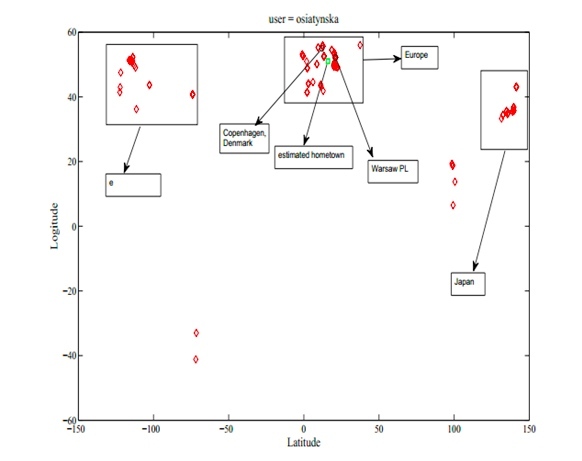
Das Team um den Informatiker Kazem Jahanbakhsh entwickelte deshalb einen Algorithmus, der es erlaubt, den Heimatort von anderen Geodaten-Clustern zu separieren. Dazu nutzten sie eine Zeitleiste und stellten darauf dann die Ortsverteilung dar. Mit Hilfe des Potenzgesetzes aus der Statistik und des Algorithmus von Kruskal, die beide beim Clustering helfen können, war es möglich, den Heimatort mit einer Genauigkeit von 70 Prozent der Fälle zu bestimmen.
Da viele Flickr-Nutzer ihre Herkunft in dem Dienst selbst offen angeben, ließ sich die Funktionsweise des Verfahrens jeweils leicht überprüfen. Die Technik von Jahanbakhsh könnte aber auch genutzt werden, um Bilder von Nutzern zu analysieren, die ihre Herkunft eigentlich geheim halten wollen. Das ginge etwa in sozialen Netzwerken wie Facebook, wo immer mehr Mitglieder dazu übergehen, nur bestimmte Teile ihrer eingestellten Informationen für das Web zu öffnen, den Rest aber nur wenigen Freunden offenlegen.
(Bild: University of Victoria)
Wenn nur Teilbereiche eines Profils zur Verfügung stehen, greifen nun aber Algorithmen wie der von Jahanbakhsh. Ein vom Nutzer in mühevoller Kleinarbeit angelegtes "sauberes" öffentliches Profil ließe sich so um fehlende Informationen, die beispielsweise Kriminelle interessieren könnten, ergänzen.
Auch ein weiteres Beispiel zeigt, dass Datenvermeidung immer noch der beste Datenschutz ist – je weniger Informationen über eine Person vorliegen, desto einfacher ist es, die Privatsphäre zu bewahren. Die Stanford-Informatikerin Aleksandra Korolova demonstrierte vor zwei Jahren in einer Studie, wie sich mit dem Facebook-Werbesystem, das jedem Interessierten, der eine Kreditkarte besitzt, offen steht, potenziell detaillierte Informationen über Nutzer des sozialen Netzwerks sammeln lassen.
Facebook nennt seine Reklametechnik Targeting: Dabei kann man genau festlegen, welche Zielgruppe man erreichen will. Korolova nutzte dies, um herauszufinden, ob ein Facebook-Mitglied homosexuell ist – selbst dann, wenn es diese Information nur seinen Freunden verrät. Die Forscherin verwendete auch hier die öffentlich verfügbaren Daten der Zielperson: Alter, Bildungshintergrund, Interessen. Ergänzt wurde dies um eine Targeting-Einstellung, die Reklame nur Personen zeigt, die sich für Menschen gleichen Geschlechts interessieren.

(Bild: University of Victoria)
Die Reklame musste anschließend nur noch von der Zielperson geklickt werden: So ermittelte Korolova nicht nur die Homosexualität ihrer Testpersonen, sondern konnte mit leicht modifizierten Anzeigen auch andere Details wie Alter, politische und religiöse Einstellungen und den Beziehungsstatus herausbekommen. Das alles koste, so die Forscherin, gegebenenfalls "nur ein paar Cent".
Facebook löste das Problem zwischenzeitlich: Nachdem Korolovas Studie bekannt geworden war, wurde das Targeting so verändert, dass sich keine Einzelpersonen mehr finden lassen – es müssen mindestens 20 Personen in einer Zielgruppe stecken. Doch das lässt sich umgehen, meint Korolova, indem man einfach 19 zusätzliche Fake-Profile erstellt. Dies koste höchstens ein paar Stunden Zeit, sagt sie. (bsc)
