

Intel verrät Details zu Core-M mit Broadwell-Kern
Intel hat den Stapellauf des neuen Core-M-Prozessors für Tablets in 14-nm-Prozesstechnik für die IFA angekündigt.

(Bild: Intel)
Kirk Skaugen, Chef von Intels Client Group, hat die IFA auserkoren, um unter dem Funkturm in Berlin den neuen Core-M-Prozessor offiziell der Weltöffentlichkeit vorzustellen. Dabei wird man wohl nicht nur das bereits auf der Computex gezeigte Referenzmodell Llama Mountain sehen, sondern auch diverse Tablet-Prototypen von Partnern. Die üblichen Verdächtigten sind Asus – das Transformer Book T300 Chi hatten sie schon auf der Computex hinter Glas gezeigt – Wistron, Acer und vielleicht auch Lenovo und Dell.
Die Core-M-Prozessoren (5Y70, 5Y10/5Y10a) seien in voller Produktion, verkündete jetzt Intel in einem Webcast vorab, erste Produkte seien fürs vierte Quartal zu erwarten.
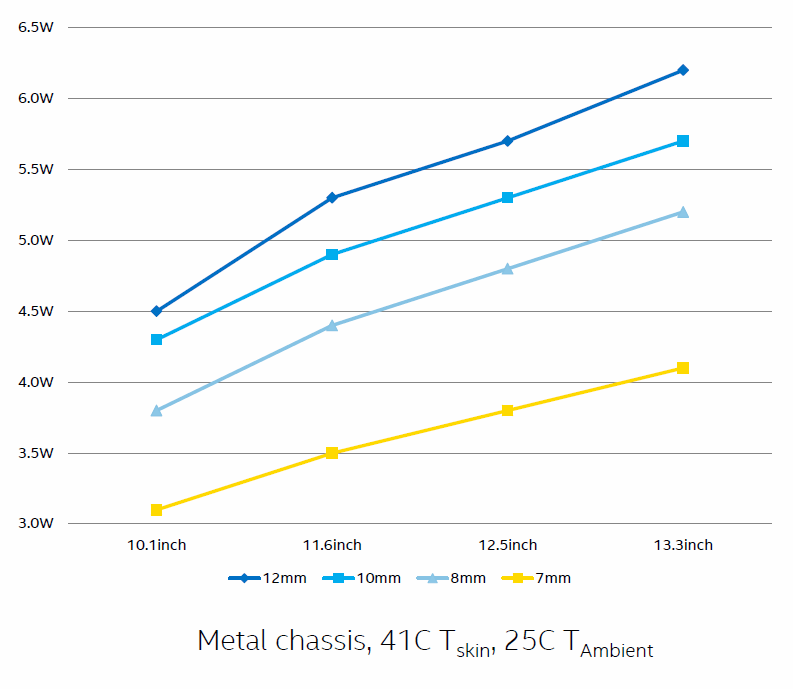
Der Zweikern-Prozessor Core M (Codename Broadwell-Y) wird als erster Vertreter in der – lange verschobenen – 14-nm-Technik gefertigt. Er ist vor allem für Tablets mit 10 bis 13,3-Zoll-Display-Größe und 7 bis 10 mm Dicke ausgelegt, und zwar ohne Lüfter. Hierfür muss sich seine Energieaufnahme (TDP) auf 3 bis 6 Watt beschränken. Taktfrequenzen gab Intel noch nicht bekannt, das Referenzmodell Llama Mountain fuhr mit einem Grundtakt von 1,3 GHz, die maximalen Turbo-Werte dürften bei 2,6 GHz liegen.
(Bild: Intel)
Broadwell ist jedoch nicht nur kleiner als der in 22-nm-Technik gefertigte Vorgänger – bei einem 1:1-Shrink hätte er nur 51 Prozent Größe des Zweikern-Haswell-U – sondern er weist auch zusätzliche Features auf, so dass er letztlich auf 63 Prozent kommt. Mit diesen Werten kann man seine Größe zu etwa 81 mm2 mit etwa 1,6 Milliarden Transistoren abschätzen. Diese zusätzlichen Features, die der ganzen Broadwell-Familie zu Gute kommt, steigern die mittlere Single-Thread-Leistung bei gleichem Takt (Instructions per Clock, IPC) um mehr als 5 Prozent.
Viel Wert hat Intel zudem auf eine Verringerung der Energieaufnahme und eine erhebliche Verkleinerung des Platzbedarfes gelegt, so dass man Tablets ohne Lüfter in weniger als 9 mm Dicke betreiben kann.
Die Energieaufnahme (TDP) wurde dazu mehr als halbiert bei gleichzeitiger Erhöhung der Performance. Im Leerlauf ist die Energieaufnahme gar um 60 Prozent geringer. Das SFF-Package, zusammen mit dem Peripherie-Chip (PCH), ist 50 Prozent kleiner und mit 1,04 mm auch 30 Prozent dünner. Das Die selbst ist nur noch 0,17 mm dick.
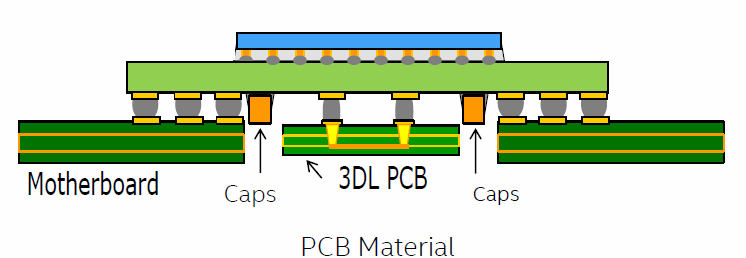
Bei dieser Dünne passen allerdings die Induktivitäten für die integrierten Spannungsregler (FIVR) nicht mehr mit hinein, und so hat sich Intel ein 3D-Induktivitäts-Modul (3DL) ausgedacht, das unter das Package kommt und das so ein rechteckiges Loch in der Hauptplatine benötigt. Der Chip unterstützt aber auch einen Bypass Mode, der die FIVR umgeht und externe Spannungen verwendet.
(Bild: Intel)
Schnellere Grafik mit 4K
Die Grafik verfügt nun über drei statt zwei "Scheiben" und damit um 50 Prozent mehr Media-Sampler als Haswell-U zuvor. Die Rechenleistung ist um 20 Prozent höher. Quick Sync wurde überarbeitet und beschleunigt und die Energieaufnahme signifikant gesenkt. HDMI 1.4a, DisplayPort 1.2, 4K-Auflösung und UHD werden laut Intel voll unterstützt sogar mit zwei Displays – aber nur dann ruckelfrei, wenn die Szenen nicht zu komplex sind. Über 30 oder 60 Hertz schwieg sich Intel allerdings noch aus. (Der aktuelle Haswell-U steuert entweder zwei 30-Hz-4K-Monitore an oder einen mit 60 Hz im Daisychain-Modus, aber Single Lane schaffen erst die Haswells ab 35 Watt TDP.) Direct-X 11.2 und OpenGL 4.3 sind für Spiele im Angebot, für Berechnungen unterstützt Core M nun OpenCL 1.2 und 2.0 mit shared virtuell memory.
Power-Management
(Bild: Intel)
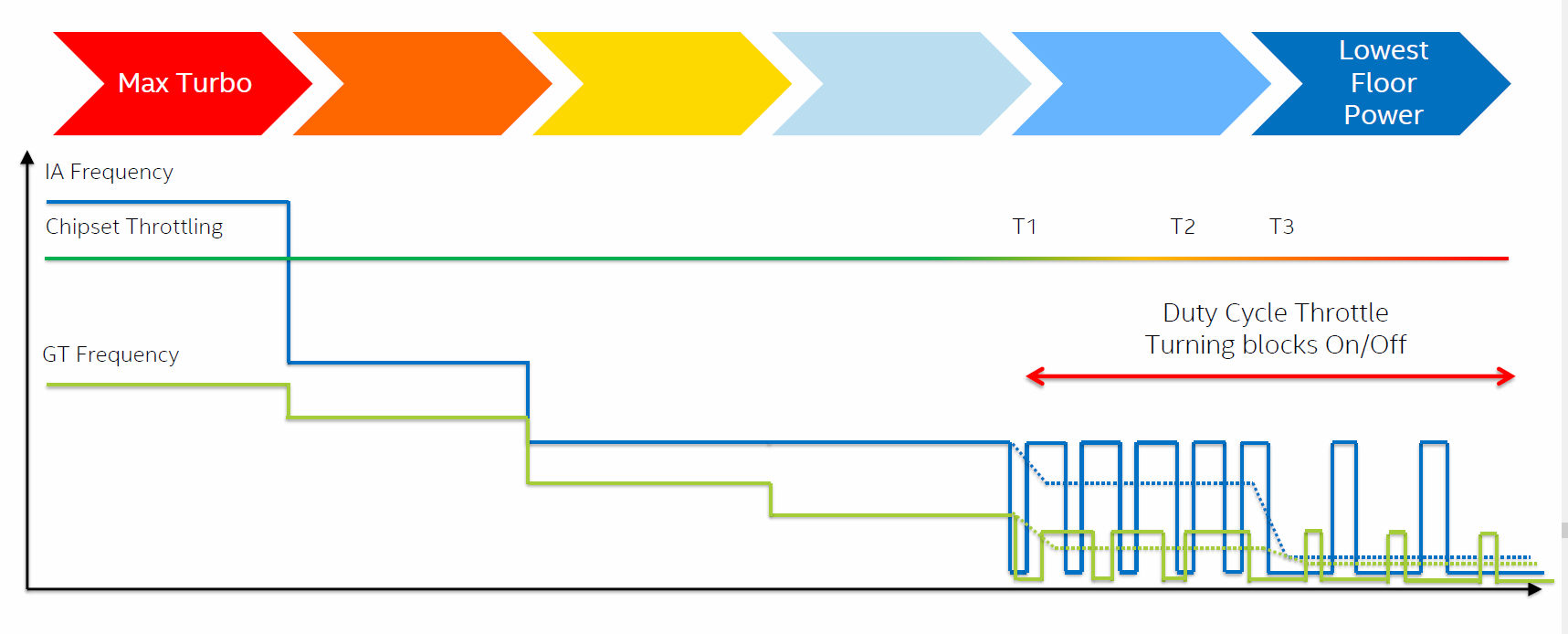
Der Turbo-Boost des Core-M arbeitet in drei Stufen. Die kurze, nur wenige Millisekunden währende Maximalstufe PL3 wird vor allem durch die Batterie-Leistungsfähigkeit begrenzt. Sie sorgt für eine sehr schnelle Response-Zeit bei interaktiven Aktionen. Der Burst-Limit PL2 kann hingegen viele Sekunden bis zu Minuten dauern, und PL1 ist dann das Langzeit-Limit des Systems. Der Turbo Modus geht in mehreren Stufen hinab auf den Grundtakt. Bei wenig anstehender Arbeit fährt er virtuell noch deutlich weiter hinunter, und zwar getogglet bis hin zu einem Arbeits/Ruhe-Verhältnis von 12,5 Prozent. Dieser Toggle-Modus bietet durch das zwischenzeitliche totale Abschalten auch ein besseres Leerlaufverhalten als ein reduzierter Takt. Das Hochfahren des Kerns bei plötzlichem Performancebedarf soll eine "kaum messbare" Zeit beanspruchen. Hinzu kommt dann noch eine Vielzahl von Design-Verbesserungen für aktive Power und Leakage. Auch der PCH-Baustein auf dem Modul – weiterhin noch in 45 nm gefertigt – verbraucht dank Verbesserungen im Design nun etwa 20 Prozent weniger (aktiv) und 25 Prozent weniger im Leerlauf.
Broadwell-Architekturerweiterungen
- Größerer out-of-order scheduler mit schnellerem store-to-load forwarding
- Größerer L2-TLB (1,5 K statt 1K Einträge)
- Zusätzlicher dedizierter L2-TLB für 1-GByte-Seiten mit 16 Einträgen
- Ein zweiter TLB-Seitenfehler-Behandler (page miss handler), der parallel zum ersten die hierarchisch aufgebauten Seitentabellen abklappert (page walks)
- Schnellerer Gleitkommamultiplizierer (3 statt 5 Takte), Radix-1,024-Dividierer, Schnelleres Gather (gleichzeitiges Lesen von verschiedenen Adressen) bei Vektorbefehlen
- Verbesserungen in der Sprungvorhersage- und der Krypto-Einheit
- Schnellere Umschaltung zwischen Hypervisor und Gast (virtualization round-trips)
Hinzu kommen kleinere Erweiterungen im Instruktionssatz wie
- ADCX und ADOX, die für Arithmetik mit großen Zahlen nützlich sind (etwa bei RSA)
- RDSEED zum Setzen des Zufallsgenerators nach den neuen NIST SP 800-90B/C-Standards
- eine von AMD übernommene PREFETCHW-Instruktion, die eine Cacheline in den Exclusive-Zustand "E" setzt
(as)
