Operations heute und morgen, Teil 4: Hochverfügbarkeit
In vielen Unternehmen gehören DevOps-Prinzipien und Cloud-Infrastruktur-Komponenten mittlerweile zum Standard. Auf dem Weg zur Hochverfügbarkeit eröffnet das neue Möglichkeiten. Doch jede Medaille hat zwei Seiten.
- Ansgar Fitz

In vielen Unternehmen gehören DevOps-Prinzipien und Cloud-Infrastruktur-Komponenten mittlerweile zum Standard. Auf dem Weg zur Hochverfügbarkeit eröffnet das neue Möglichkeiten. Doch jede Medaille hat zwei Seiten. Komplexe und vernetzte System- und Anwendungslandschaften stellen den Betrieb weiterhin vor Probleme, und Hochverfügbarkeit bleibt eine Herausforderung.
Geschäftsprozesse sind die Basis jeder Wertschöpfung. Das erfordert zum einen eine klar strukturierte und reibungslos arbeitende IT-Organisation, zum anderen, dass die benötigten technischen Systeme auf Ausfallsicherheit und Korrektheit ausgerichtet sind. Anders ausgedrückt: Hochverfügbarkeit ist ein wichtiger Erfolgsfaktor. Viele Unternehmen haben dafür unter anderem ihre IT-Organisation nach DevOps-Prinzipien aufgestellt und Cloud-Infrastrukturen eingeführt.
Definition und Struktur von Verfügbarkeit
Operations heute und morgen
Das Business scheint aus IT-Sicht seine Anforderungen und Wünsche nach neuen und aktualisierten Features immer schneller zu ändern. Gleichzeitig gibt es innerhalb der IT fortwährend neue Trends, die umgesetzt werden wollen. Doch wo steht der IT-Betrieb bei der Umsetzung der Anforderungen und Wünsche? Haben die Entwickler mit dem agilen Trend die Mauern zum Business eingerissen, kam in den letzten Jahren zunehmend der Wunsch nach DevOps auf. Dev steht für Development/Entwicklung und Ops für Operations/Betrieb. Damit soll auch die Mauer zwischen Entwicklung und Betrieb überwunden werden. Doch was hat sich bisher wirklich durchgesetzt? Das betrachtet die Artikelserie "Operations heute und morgen":
Verfügbarkeit (engl. 'availibility') bedeutet im Allgemeinen die Bereitschaft oder das Vorhandensein. Im Zusammenhang mit Prozessen und technischen Systemen fällt häufig auch der Begriff Zuverlässigkeit. Aber Obacht – Verfügbarkeit und Zuverlässigkeit sind zwei verschiedene Dinge (vgl. [2]). Zuverlässigkeit, im Engl. 'reliability', ist die Wahrscheinlichkeit, dass ein System störungsfrei, ohne Fehler über einen möglichst langen Zeitraum funktioniert. Während Verfügbarkeit den relativen Anteil des Zeitraums angibt, in dem das System seine Aufgabe beziehungsweise Funktion erfüllt, selbst wenn Fehler auftreten.
Ein Beispiel: Ein System das jede Stunde 3,6 Sekunden nicht vorhanden ist, ist mit 99,9 Prozent hochverfügbar, jedoch sehr unzuverlässig. Steht ein System dagegen für den Zeitraum von einer Woche im Jahr nicht zur Verfügung, ist es sehr zuverlässig, aber mit circa 98 Prozent nicht wirklich hochverfügbar.
Steht ein System nicht zur Verfügung, liegt ein Systemausfall oder ein Systemversagen vor, im Englischen 'failure' (Systemverhalten passt nicht zur Systemspezifikation). Ursache sind Fehler ('error'), die ein Fehlerverhalten ('fault') erzeugen. Alle drei Typen werden als Fehler übersetzt und meist auch synonym verwendet. Geht es wie in diesem Artikel um Fehler im Kontext von Hochverfügbarkeit, sind "Failures" und damit
Systemausfälle und Systemversagen gemeint. Die einschlägige Literatur (siehe z. B. [2]) unterscheidet typischerweise fünf Fehlertypen im Kontext von Verfügbarkeit:
- Crash Failure (Absturzfehler): Ein System antwortet permanent nicht mehr, hat bis zum Zeitpunkt des Ausfalls aber korrekt gearbeitet.
- Omission Failure (Auslassungsfehler): Ein System reagiert auf (einzelne) Anfragen nicht, weil es die Anfragen nicht erhält oder keine Antwort sendet.
- Timing Failure (Antwortzeitfehler): Die Antwortzeit eines Systems liegt außerhalb eines festgelegten Zeitintervalls.
- Response Failure (Antwortfehler): Die Antwort, die ein System gibt, ist falsch.
- Byzantine Failure (byzantinischer/zufälliger Fehler): Ein System gibt zu zufälligen Zeiten zufällige Antworten ("es läuft Amok").
Die meisten Personen denken bei Systemausfällen und Systemversagen vor allem an Absturzfehler. Es ist aber wichtig zu berücksichtigen, dass alle Fehlerklassen in die Verfügbarkeit einfließen. Es geht demnach nicht nur darum, die relativ einfach zu handhabenden Absturzfehler zu behandeln, sondern alle Fehlertypen, also zum Beispiel auch zu langsame oder falsche Antworten zu erkennen und damit umzugehen.
Verfügbarkeit wird üblicherweise als Größe zwischen 0 Prozent ("gar nicht verfügbar") und 100 Prozent ("voll verfügbar") ausgedrückt. Die Welt ist unvollkommen, und Fehler werden passieren, deshalb wird von Hochverfügbarkeit gesprochen, was bedeutet, den Prozentsatz möglichst nah an die Vollverfügbarkeit (100 %) zu bringen. Mit der "Anzahl der Neunen" wächst die Verfügbarkeit, zum Beispiel "3 Neunen" (0,999/9,9 %, < 7 h Downtime/Jahr), "4 Neunen" (0,9999/99,99 %, < 1 h Downtime/Jahr) oder "5 Neunen" (0,99999/99,999 %, < 6 Min. Downtime/Jahr). Verfügbarkeit wird nach Robert S. Hanmer [2] und dem BSI-Kompendium Hochverfügbarkeit [3] wie folgt berechnet:
Verfügbarkeit := MTTF / (MTTF + MTTR)
Dabei enstpricht MTTF ('mean time to failure') dem Zeitraum bis zum Ausfall beziehungsweise Fehler des Systems. MTTR ('mean time to repair') ist der Zeitraum von der Erkennung bis zur abschließenden Behebung beziehungsweise Reparatur des Fehlers. Das Ergebnis kann damit die Werte zwischen 0 für "gar nicht verfügbar" und 1 für "immer verfügbar" annehmen. Wird dieser Wert mit 100 multipliziert, erhält man die vertraute Darstellung in Prozent.
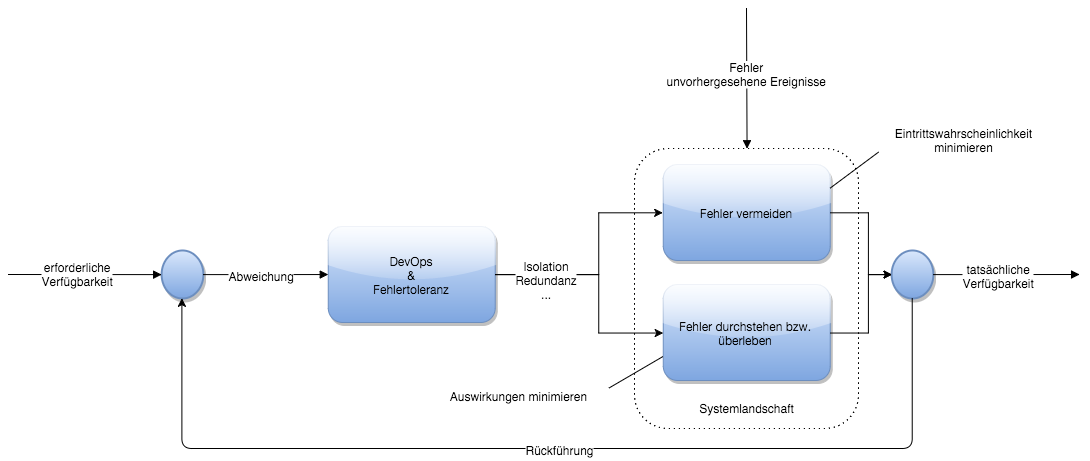
Nun gibt es zwei Möglichkeiten, die Verfügbarkeit, wie in der folgenden Abbildung anhand des Regelkreislaufs zu beeinflussen:
- Erhöhung der MTTF: die Lebensdauer erhöhen, damit der Wert für MTTR vernachlässigbar klein wird.
- Verkürzung der MTTR: den Zeitraum für die Reparatur so "klein" wie möglich machen, sodass der Wert im Verhältnis zur MTTF ebenfalls vernachlässigbar klein wird.