Egal ob Spracherkennung oder Robotersteuerung: Sagen simulierte Neuronen die Zukunft voraus, eignen sie sich für intelligente Systeme. Ein System vom Max-Planck-Institut lernt die nötigen Muster mit wenigen oder ganz ohne Rückmeldungen von einem Lehrer.
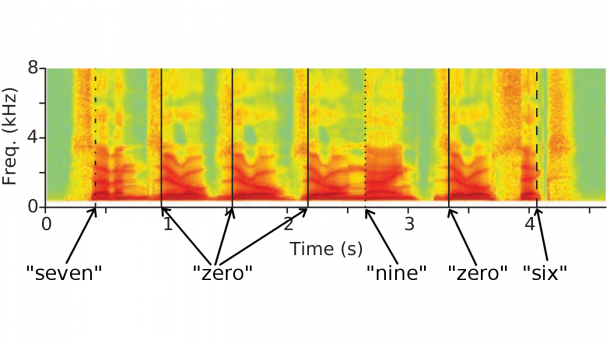
Spektrogramm einer Sprachaufnahme in der die Ziffern 7000906 vorgelesen werden: Die Linien geben an, an welchen stellen das neuronale Netz Ziffern erkannt hat.
Der Forscher Robert Gütig vom Max-Planck-Institut für experimentelle Medizin hat in der Science ein Verfahren vorgestellt, mit dem simulierte Neuronen auch ohne Lernsignal relevante Muster aus Trainingsdaten lernen. Als relevant stufen die Neuronen Abfolgen von Signalen ein, die dabei helfen, zukünftige Signale vorherzusagen. Die Neuronen in der Simulation registrieren wie oft die über Synapsen verbundenen Neuronen gefeuert haben und reagieren selbst mit einer erlernten eigenen Zahl an Aktivierungen. Speiste Gütig die gemeinsame Aktivierung aller Neuronen als Lernsignal zurück ins Netzwerk, lernte dies ganz ohne externe Labels - allerdings etwas langsamer.
Weiterlesen nach der Anzeige
Computational Neuroscience
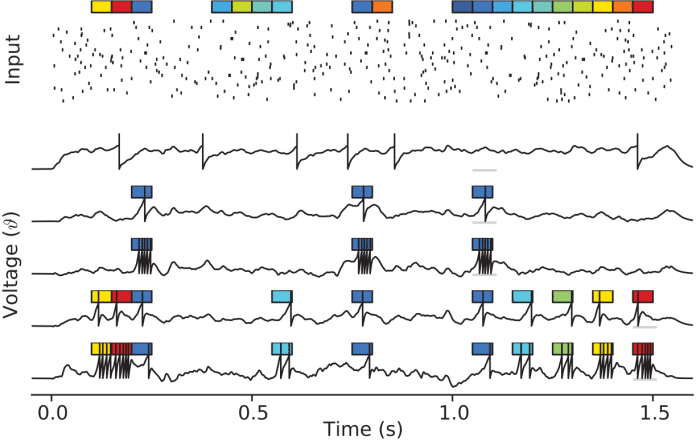
Von der Natur abgeschaut: Empfangen die Neuronen über ihre Synapsen besonders starke Reize, feuern sie gleich mehrmals. Durch das Training passiert das nur bei bestimmten Reizmustern.
(Bild: Robert Gütig)
Gütigs Simulation bleibt sehr nah an den Erkenntnissen der Hirnforschung und versucht im Gegensatz zum momentan sehr beliebten Thema Deep Learning wirklich die Vorgänge in Gehirnzellen zu simulieren. Damit gehört die Arbeit in den Bereich Computational Neuroscience und nicht zum Machine Learning. Dort dürfte sie aber durchaus auf Interesse stoßen: Gütig hat sein System mit Lernverfahren aus den Reinforcement Learning verglichen und deutliche Verbesserungen erzielt. Beim Reinforcement Learning gibt es erst nach einer Reihe von Aktionen eine Rückmeldung, ob diese gut oder schlecht für den Agenten waren. Das Problem zuzuordnen, welche der Aktionen für Erfolg oder Misserfolg maßgeblich war, konnten die bisherigen stochastischen Methoden nur sehr langsam lösen. Die aggregierten Label aus Gütigs Verfahren scheinen hier viel schneller zu einer Lösung zu kommen.
Auch die Lernerfolge ohne konkrete Zielfunktion faszinieren. Bei Big-Data ist es oft zu teuer ausreichend große Datensätze mit Labeln zu versehen, da Menschen diese Aufgabe übernehmen müssen. Datenmassen auch ohne Labels durchforsten zu können, dürfte bei Facebook, Google oder Microsoft Interesse wecken. Für eine direkte Anwendung auf wirklich große Datensätze ist die bionische Simulation bisher aber vermutlich noch zu komplex.
(pmk)