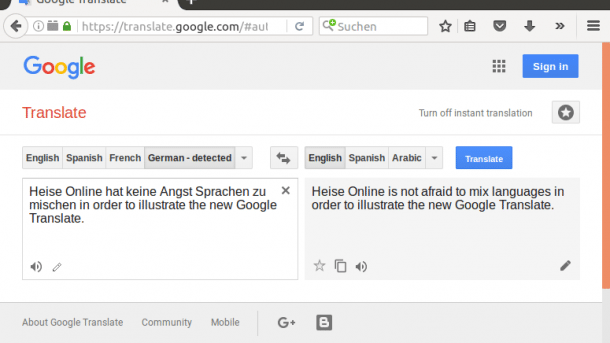
Google: Translate-KI übersetzt dank selbst erlernter Sprache
Google Translate übersetzt ab sofort mit einem einzigen neuronalen Netz von jeder der 103 unterstützten Sprachen in jede andere – sogar wenn es für ein Sprachpaar nicht mit Beispielsätzen lernen konnte. Übersetzungen in seltene Sprachen profitieren davon.
Google hat seinen Übersetzungsdienst Translate auf ein einzelnes neuronales Netz umgestellt, das alle 103 Sprachen beherrscht. Damit kümmert sich nicht mehr jeweils ein eigenes neuronales Netz um ein Paar aus Quell- und Zielsprache. Mit dem multilingualen Translate spart sich Google den Aufwand Tausende Übersetzungssysteme für einzelne Sprachpaare zu pflegen und verbessert gleichzeitig die Qualität der Übersetzungen bei Sprachpaaren, zu denen Google weniger Trainingsdaten besitzt.
Weiterlesen nach der Anzeige
In einem Blogpost erklärt Google, dass das System sogar sinnvoll zwischen Sprachen übersetzt, bei denen gar keine Trainingsbeispiele für die direkte Übersetzung vorlagen. Wurde das System mit Beispielen zwischen Englisch und Japanisch und Englisch und Koreanisch trainiert, war es anschließend auch in der Lage zwischen Japanisch und Koreanisch zu übersetzen. Google vermutet daher, dass ihr Übersetzungssystem intern eine Universalsprache erlernt.
Die Technik hinter Google Translate
Google Translate besteht aus drei verzahnt arbeitenden neuronalen Netzen. Ein rekurrentes neuronales Netz mit acht Schichten aus LSTM-Neuronen (Long-Short-Term-Memory) liest die Wortteile der Eingaben. Dabei liest die erste Schicht den Satz sowohl von vorne nach hinten als auch von hinten nach vorne. LSTMs können Informationen speichern, die ihnen bei vorherigen Datensätzen begegnet sind. Damit kann die erste Schicht Wortteile sinnvoll interpretieren, deren Bedeutung von anderen Wortteilen im Satz beeinflusst wird. Ab Schicht zwei arbeitet das Decoder-Netzwerk dann nur von vorne nach hinten.
LSTMs mit mehr als vier Schichten lassen sich normalerweise nicht effizient trainieren. Google überspringt daher jede Schicht mit einer zusätzlichen Residual-Verbindung, die die Aktivierung der Eingaben auf die Ausgaben addiert. Mit diesem Trick ist es Microsoft gelungen ein sehr tiefes convolutional neuronal network zu trainieren und damit den letzten ImageNet-Wettbewerb für Bilderkennung zu gewinnen.
Die Ausgabe des Dekoders ist eine Reihe von vieldimensionalen Vektoren mit fester Breite. Diese stellen die "Worte" in der von Google vermuteten Universalsprache dar. Außerdem dienen sie als Eingabe für das Encoder-Netzwerk, das ebenfalls aus acht LSTM-Schichten besteht. Das bekommt noch zusätzliche Hinweise von einem kleinen Netzwerk aus normalen Neuronen mit nur drei Schichten. Das kleine Netz dient dazu, die Aufmerksamkeit des Decoders auf wichtige Teile des Satzes zu lenken.
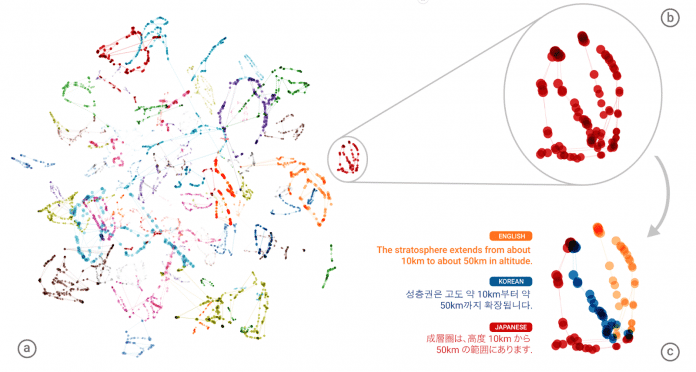
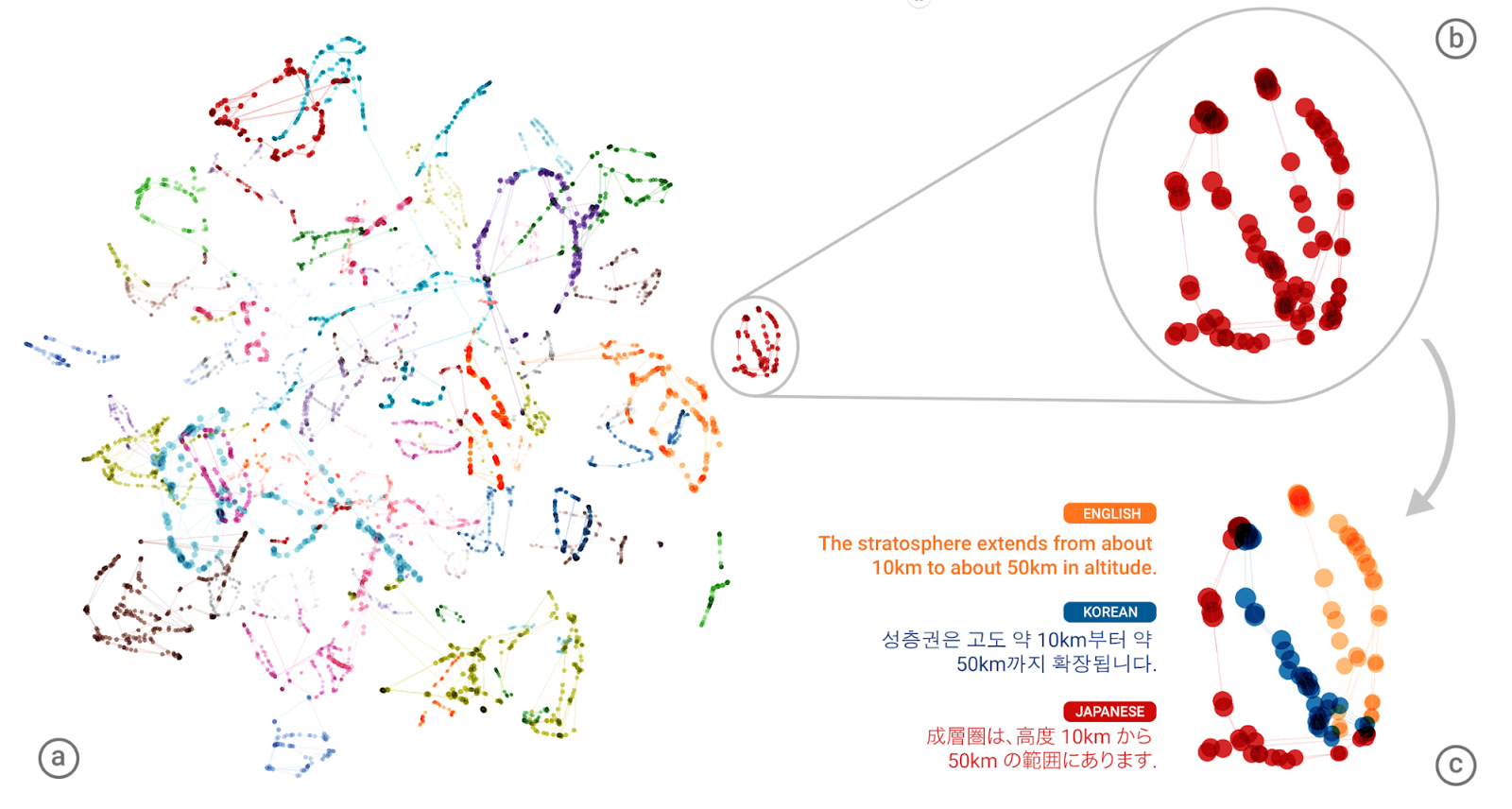
Die Vektoren innerhalb des neuronalen Netzes an der Schnittstelle zwischen Decoder und Encoder liegen bei bedeutungsgleichen Sätzen in verschiedenen Sprachen nahe beieinander.
(Bild: Google)
In einem zweiten Paper erläutert Googles Forschungsteam (PDF), warum das Netzwerk vermutlich eine Universalsprache lernt. Die Forscher transformierten die Vektoren an der Trennstelle zwischen Decoder und Encoder mit dem t-SNE-Algorithmus in den dreidimensionalen Raum. Dabei kamen für die Sätze aus verschiedenen Quellsprachen Punkte heraus, die nahe beieinander lagen. Übersetzte das Netzwerk zwischen einem Sprachpaar, für das es keine Beispiele in den Trainingsdaten gab, lagen die Vektoren ebenfalls nahe bei den Sätzen der anderen Sprachen.
Ganz universell scheint die Zwischenrepräsentation aber nicht zu sein, da Google die Zielsprache als besonderen Wortteil in die Eingabedaten integriert. Aber auch wenn Google noch nicht den Heiligen Gral der Linguistik gefunden hat, beweist die Translate-KI, dass sie zu einem gewissen Grad die Bedeutung von Sätzen kodiert. Damit kommt die KI dem Verstehen natürlicher Sprache einen großen Schritt näher.
Mehr zu neuronalen Netzen:
Die Mathematik neuronaler Netze: einfache Mechanismen, komplexe Konstruktion (c't 6/16, S. 130, kostenlos)