

Analyse: AMD und die Kunst des Benchmarkings
AMD will auch beim aktuellen Hype-Thema "maschinelles Lernen" mitmischen und hat DeepBench-Werte für die nächste GPU-Generation Radeon Vega FE veröffentlicht – aber wie kamen die zustande und was sagen sie aus?
(Bild: AMD)

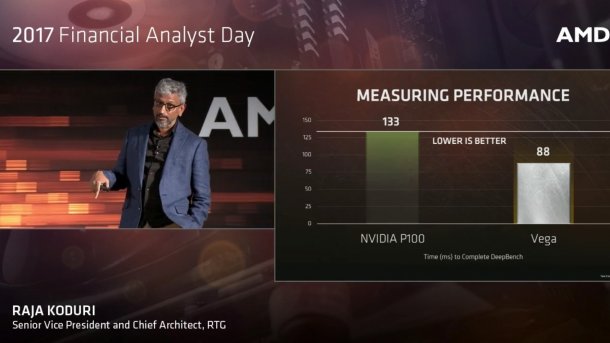
AMD hat schöne Benchmarkergebnisse zur Radeon Vega Frontier Edition für Deep Learning veröffentlicht und zwar im Vergleich zu Nvidia P100, Tesla M40 und Intel Xeon Phi 7250. Mit 88 ms "Durchlaufzeit" wäre die neue Karte beim DeepBench von Baidu viel schneller als die P100, die in der Präsentation mal mit 133 ms auftaucht (auf 2 ×Xeon E5-2640v4 mit Nvidia Driver 375.39), mal mit 122 ms (auf 2 × Xeon E5-2667v4 mit Driver 375.51). Die Tesla M40 wird mit 288 ms angegeben und das Xeon-Phi-7250-System mit 569 ms. Nur was ist das für eine Zeit? DeepBench kennt so einen Wert als solchen nämlich gar nicht.
Tieferer Blick
Ein tieferer Blick auf die auf der Github-Seite Baidu-Research veröffentlichten Werte offenbart, dass es sich hierbei um einen Teil der Benchmark-Suite handelt, der unter "Convolution" läuft. Dieser besteht aus 36 Einzelbenchmarks mit unterschiedlichen Matrix-Größen, Parametern und Algorithmen. Der Benchmark-Report gibt für jeden zwar die einzelnen Laufzeiten für Forward und Backward aus, als eigentliches Ergebnis wird dann aber die jeweilige Performance in TFlops/s angegeben, nur kann man das nicht so leicht zusammenzählen. Konkurrent Intel hat dann auch entsprechende Kurven in TFlops/s für alle 36 Einzelbenchmarks von DeepBench Convolution veröffentlicht, mit den Werten von Baidu.
AMD Benchmarks für Radeon Vega FE (3 Bilder)

(Bild: AMD)
Einmal Aufaddieren, bitte!
AMD addiert hingegen einfach die 36 Gesamtlaufzeiten für Forward und Backward auf, die etwa beim Xeon Phi um Faktor 1000 zwischen 0,11 ms und 101 ms variieren. Mit einer guten Benchmark-Praxis, wie sie zum Beispiel in der Bibel des Benchmarkings "The Art of Computer Systems Performance Analysis" von Raj Jain eingefordert wird, hat das nicht viel zu tun, denn danach wäre hier ein geometrisches Mittel gefordert. Und selbst beim einfachen Zusammenzählen der 36 Werte hat sich AMD nicht viel Mühe gegeben, beim Xeon Phi 7250 stimmt's noch, aber bei der Tesla M40 – AMD bezieht sich explizit auf die erwähnte Github-Seite – kommt unser Excel-Sheet jedenfalls auf 226 statt 288 ms.
Die Messungen für die Tesla P100 in der langsameren PCIe-Version hat AMD offenbar selbst durchgeführt, auf Github ist indes die bei FP32 üblicherweise dank höherem Takt um etwa 15 bis 20 Prozent schnellere Titan-X (Pascal) gelistet, mit einer Convolution-Gesamtdurchlaufzeit von 113 ms.

(Bild: AMD )
In der Video-Präsentation zeigt AMD immerhin ein Diagramm mit getrennt nach Matrix-Größen aufaddierten Ergebnissen, von 1×1 bis 5×20. Aber warum braucht gemäß dieses Diagramms die von AMD vermessene P100 (die mit 133 ms) bei den Matrixgrößen 5×20, 7×7 und 1×1 gut doppelt so lange wie die Titan X-Pascal auf der Baidu-Seite? Fragen über Fragen.
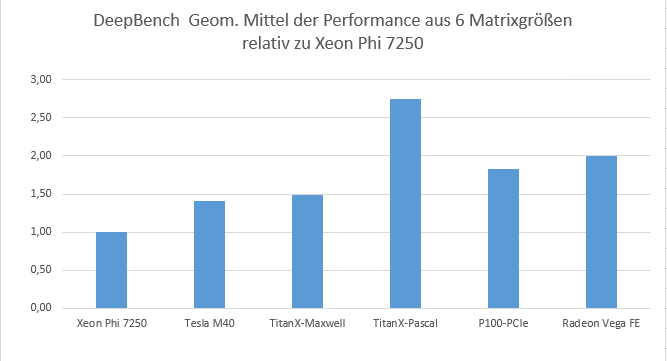
Wir haben die Ergebnisse getrennt für die sechs Matrixgrößen in geometrischer Mittelung relativ zum Xeon Phi 7250 dargestellt, und zwar nicht als Laufzeit, sondern als Performance, damit man die hübschere Darstellung höher= besser erhält. Danach wäre die Titan X-Pascal 2,75 mal so schnell wie Intels Xeon Phi und damit klar vor der Radeon Vega FE (2,0 mal), der P100-PCIe (1,83) und der M40 (1,4).
(Bild: c't)
Bibliotheken
Zum Xeon Phi müsste man noch anmerken, dass der vom CudaDNN angebotene Winograd-Algorithmus, den 13 der 36 Einzelbenchmarks von Deepbench Convolution bei Nvidia-Karten nutzen, in der aktuellen Intel MKL noch nicht implementiert ist – daran arbeitet Intel noch. Von AMD weiß man nur, dass ROCm 1.5 und OpenCL 1.2 beim DeepBench zum Einsatz kamen. Einzelheiten über die verwendeten Bibliotheken und Algorithmen kennt man nicht.
Vermutlich ist es die für HIP konzipierte RocBLAS. Die kennt immerhin auch Polaris, anders als die etwas vernachlässigte aktuelle clBLAS V2.12 für C++ und clang, bei der immer noch bei Fiji (GCN3) Schluss ist. Beide Bibliotheken werden von AMDs Software-Ingenieur Tingxing (Tim) Dong mitgepflegt. RocBLAS dürfte auch mit dem CUDA-Code von DeepBench klarkommen, denn es kann auch für Nvidia-Karten unter CUDA eingesetzt werden.
Es gibt auch noch andere Bibliotheken, die sowohl OpenCL als auch CUDA unterstützen und die gerade für SGEMM und DeepBench noch mehr Beschleunigungspotential bieten, etwa die vom MIT entwickelte ISAAC-Kombibliothek für CUDA und OpenCL – die übrigens auch schon AMD Polaris (GCN4) kennt. ISAAC erzeugt nicht nur Code für Machine Learning, sondern nutzt Machine Learning auch zur Optimierung des Codes. (as)
