Effiziente Datenverarbeitung mit Kafka
Kappa-Architekturen sind der nächste Evolutionsschritt im Fast-Data-Umfeld. Damit lohnt sich ein Blick darauf, wie Apache Kafka sich vom reinen Message-Broker zu einer Streaming-Plattform weiterentwickelt hat und wie man mit Kafka-Bordmitteln eine Kappa-Architektur aufbauen kann.

- Florian Troßbach
Durch die zunehmende Digitalisierung ist in vielen Unternehmen die Menge der täglich zu verarbeitenden Daten immens angestiegen, sodass in manchen Kreisen bereits Ende der 1990er Jahre der Begriff "Big Data" fiel. Spätestens seit dem zweiten Jahrzehnt des 21. Jahrhunderts ist das Thema im Mainstream angekommen. Die ersten Big-Data-Plattformen orientierten sich an der bekannten Batch-Verarbeitung. Unternehmen haben die anfallenden Daten tagsüber gesammelt und nachts verarbeitet. Eine der am weitesten verbreiteten Plattformen für dafür ist Apache Hadoop mit den Hauptkomponenten HDFS (Hadoop Distributed File System, verteiltes Dateisystem) und MapReduce für die eigentlichen Batch-Jobs.
Grenzen der Batch-Verarbeitung
Eine nächtliche Verarbeitung hat freilich Nachteile: Im schlimmsten Fall sind eingehende Daten erst 24 Stunden später in den Folgesystemen verfügbar. Als Reaktion darauf entstanden Lambda-Architekturen, die die Batch-Verarbeitung um einen Speed- und einen Serving-Layer ergänzte, um zumindest vorläufige Aussagen echtzeitnah bereitstellen zu können. Speed- und Batch-Ebene erhalten die Inhalte aus derselben Nachrichtenquelle (vgl. Abb. 1). Auf Abfrageseite im Serving-Layer erfolgt der Abruf und die Aggregation der Batch- und Echtzeitdaten aus den Speichersystemen der jeweiligen Schicht, sodass der Aufrufer ein aktuelles Bild der Daten erhält, das im Laufe der Zeit – in der Regel im nächsten Batch-Durchgang – verfeinert wird.

Ein populärer Vertreter der Lambda-Architekturen ist seit etwa 2015 unter dem Namen "SMACK Stack" bekannt. Der Name ist ein Akronym der Bestandteile Apache Spark, Apache Mesos, Akka, Apache Cassandra und Apache Kafka. In einer solchen Architektur dient Spark als Streaming-Engine für den Speed-Layer und als Batch-Engine. Das System stellt die Echtzeitdaten über Kafka bereit und speichert die Ergebnisse persistent in Cassandra. Mesos verwaltet die Hardwareressourcen im Cluster, und Akka bietet ein hervorragend skalierendes Programmiermodell für den Dateneingang und die Datenabfrage. Der Markt ist allerdings stark in Bewegung, weshalb die SMACK-Kombination bei einigen in der Fast-Data-Community schon als veraltet gilt – wohlgemerkt der Stack, nicht die einzelnen Komponenten. In neueren Projekten übernimmt Kubernetes häufig die Ressourcenverwaltung. Das ereignisorientierte Framework Vert.x ist direkter Konkurrent von Akka.
Cassandra ist nach wie vor weit verbreitet, passt aber nicht zu jedem Anwendungsfall. Spark ist nach Meinung des Autors weiterhin das Batch-Framework der Wahl, hat aber im Streaming-Bereich starke Konkurrenz unter anderem durch Apache Flink. Für den Message-Broker Kafka gibt es im Big-Data-Umfeld keinen wirklichen Herausforderer. Nahezu alle freien Streaming-Frameworks unterstützen Kafka. Die hauptsächlichen Wettbewerber sind Cloud-native Lösungen wie Kinesis von Amazon oder Cloud Pub/Sub von Google, die jedoch nur in der jeweiligen proprietären Cloud-Umgebung verfügbar sind.
Von Lambda zu Kappa
Es gibt einige Kritikpunkte an der Lambda-Architektur. Entwickler müssen in Batch- und Speed-Layer oft ähnliche Funktionen implementieren, die sich in vielen Fällen nicht einfach übertragen lassen. Wer Frameworks nutzt, die Batch- und Speed-Layer-Logik abstrahieren, ist auf den kleinsten gemeinsamen Nenner beider Schichten festgelegt. Aus operativer Sicht hat eine Lambda-Architektur den Nachteil, dass komplexe verteilte Systeme zu betreiben und überwachen sind. Über allem steht die Frage, ob der Batch-Layer überhaupt noch zeitgemäß ist. Lässt sich nicht der Speed-Layer dermaßen mächtig gestalten, dass sich darin alle relevanten Berechnungen in Echtzeit durchführen lassen?
An dem Punkt setzt die Idee der Kappa-Architektur an. Der Ansatz ist, den Batch-Layer komplett zu streichen, da der Speed-Layer ausreicht, um alle erforderlichen Berechnungen durchzuführen. Die Kernidee ist jedoch folgender Paradigmenwechsel: Die Rolle der kanonischen Datenquelle, die in einer Lambda-Architektur in den Datensenken der jeweiligen Layer liegen, lässt sich in einer Kappa-Architektur auf die gepufferte Datenquelle verlagern. Eine Streaming-Schicht verarbeitet die Daten und stellt die Ergebnisse über einen Serving-Layer bereit. Eine Änderung der Berechnungslogik ist denkbar einfach: Nach dem Ausrollen liest eine aktualisierte Version alle gepufferten Nachrichten erneut in der originalen Reihenfolge. Die Ergebnisse schreibt sie in eine neue Datensenke und kann die Daten der vorherigen Version im Anschluss löschen (vgl. Abb. 2). Das reduziert die Komplexität der kompletten Architektur deutlich, obwohl es sich weiterhin um ein verteiltes System handelt.

Fallbeispiel: Von Lambda zu Kappa
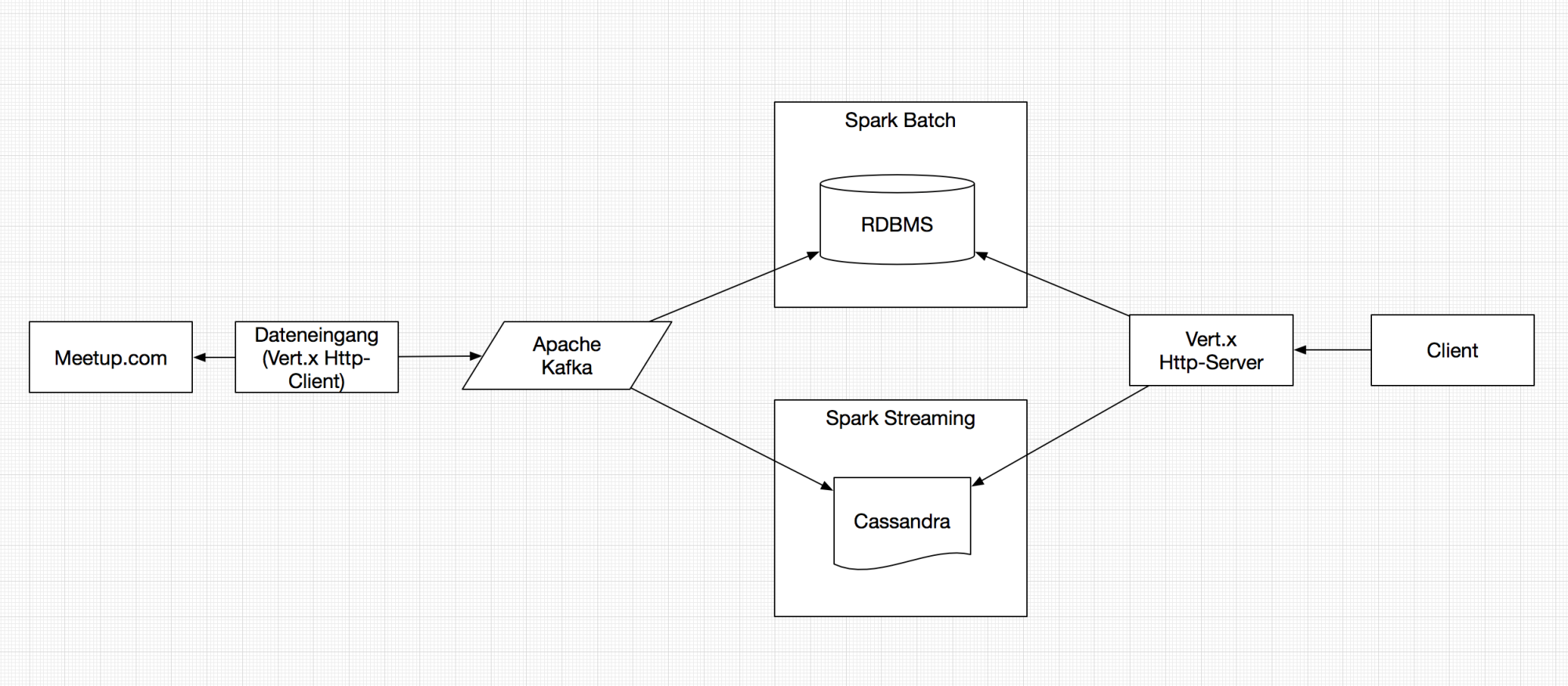
Die Migration einer Lambda-Architektur auf Kafka soll die aktuellen Fähigkeiten des Tools als Streaming-Plattform demonstrieren. Der Dienst Meetup.com ist ein soziales Netz, über das sich Interessensgruppen zu den unterschiedlichsten Themen wie IT, Sport oder Stricken bilden und ihre Offline-Treffen organisieren können. Interessanterweise stellt Meetup.com über einen Websocket in Echtzeit Daten für Zu- und Absagen zu den Treffen öffentlich zur Verfügung. Um das Beispiel möglichst einfach zu halten, beantwortet die Beispielanwendung folgende einfache Frage: Wie viele Ab- und Zusagen treten pro Stadt auf?
Eine klassische Lambda-Architektur könnte aussehen wie in Abbildung 3. Im Dateneingang werden die von Meetup.com gelieferten Daten in ihrem nativen JSON-Format in ein Kafka Topic geschrieben. JSON fördert die Einfachheit des Beispiels – in der Realität käme vermutlich ein schemabehaftetes Datenformat wie Apache Avro zum Einsatz. Die Nachrichten werden mit Spark Streaming aggregiert und die Ergebnisse in Cassandra persistiert. Die Abfrage der Daten erfolgt über eine Webanwendung.