

Apache Hadoop 3.1.0 beherrscht GPU- und FPGA-Pooling
Zahlreiche Fehlerbereinigungen und neue Funktionen sollen Hadoop 3.1 für Microservices und die Anbindung containerisierter Anwendungen optimieren. Für den produktiven Einsatz ist das Release jedoch noch nicht freigegeben.

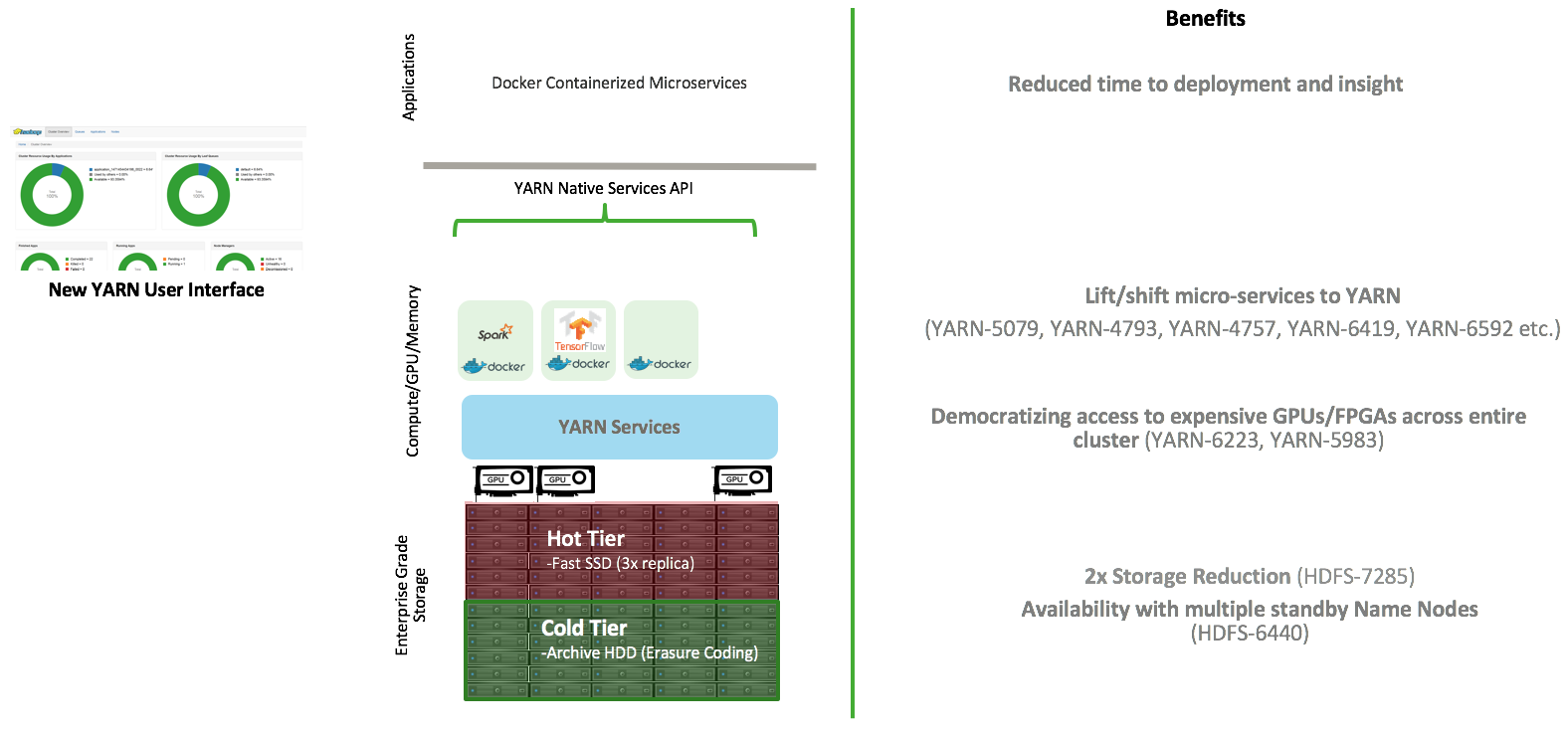
Rund fünf Monate nach Freigabe des Major Release Hadoop 3.0.0 legt die Apache Software Foundation nun Version 3.1.0 nach, mit Hunderten Bugfixes sowie einer Reihe von Optimierungen und neuen Funktionen. Die wesentlichen Neuerungen betreffen HDFS und YARN. Sie legen die Basis, um Microservices unmittelbarer an einen Hadoop Data Lake anzubinden. Die native YARN Services API verschafft dazu containerisierten Anwendungen – darunter auch Deep-Learning-Frameworks wie TensorFlow oder Caffe – Zugriff auf die Datenspeicher. Erasure Coding verspricht daneben eine Optimierung der Total Cost of Ownership, in dem sich der Speicherbedarf besser regulieren lässt. Die neue Funktion soll den Storage Overhead von 200 auf 50 Prozent senken können.
(Bild: Apache)
Komplett überarbeitet haben die Macher die Verwaltung von GPU- und FPGA-Ressourcen. Anstatt Data Scientists einzeln mit GPU-Hardware auszustatten, lassen sich sämtliche, auch serverseitig installierten GPUs poolen oder isolieren, um sie entweder für eine gemeinsame oder aber exklusive Nutzung zu reservieren. Separate Compute/GPU-Cluster für die Deep-Learning-Algorithmen und das Training der Modelle mit den im Data Lake gesammelten Daten sollen dadurch überflüssig werden. Gegenüber einem CPU-basierten Ansatz soll die neue für Microservices optimierte Architektur einen Geschwindigkeitsvorteil bis zum Faktor 100 erzielen. Alternativ zu GPUs können auch im Cluster vorhandene FPGAs auf die gleiche Weise flexibel zugewiesen werden.
Eine Übersicht sowie nähere Details zu sämtlichen Neuerungen finden sich in den Release Notes. Apache Hadoop 3.1.0 steht ab sofort zum Download zur Verfügung, ist von der Foundation aber explizit noch nicht für den produktiven Einsatz freigegeben, da noch einige kritische Punkte "ausgebügelt" werden müssten. Anwender, die die Software in der Produktion nutzen wollen, sollen daher die Veröffentlichung von Version 3.1.1 oder 3.1.2 abwarten. (map)
