

C++ Core Guidelines: Regeln zur Concurrency und zur Parallelität
C++11 war der erste C++-Standard, der sich mit Concurrency beschäftigt. Der zentrale Baustein für Concurrency ist ein Thread. Dies ist der Grund, dass die meisten der Regeln sich mit Threads beschäftigen. Dies ändert sich dramatisch mit C++17.
- Rainer Grimm
C++11 war der erste C++ Standard, der sich mit Concurrency beschäftigt. Der zentrale Baustein für Concurrency ist ein Thread. Dies ist der Grund, dass die meisten der Regeln sich mit Threads beschäftigen. Dies ändert sich dramatisch mit C++17.
Mit C++17 wurde die Programmiersprache um die parallelen Algorithmen der Standard Template Library (STL) erweitert. Das bedeutet, dass die meisten der Algorithmen der STL sequenziell, parallel oder vektorisiert ausgeführt werden können. Für den neugierigen Leser: Ich habe bereits zwei Artikel zu der parallelen STL geschrieben. Der Artikel "Parallele Algorithmen der Standard Template Library" erklärt detailliert die Ausführungsstrategie, mit der sich die sequenzielle, parallele oder vektorisierte Ausführung der Algorithmen steuern lässt. C++17 wurde aber auch um neue Algorithmen erweitert, die für die parallele oder vektorisierte Ausführung konzipiert sind. Hier sind die Details: "Neue Algorithmen in der C++17".
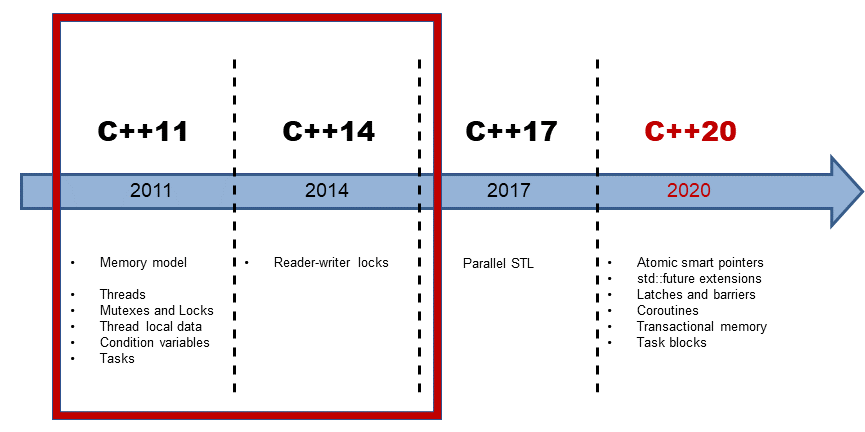
Die Concurrent-Geschichte in C++ geht weiter. Mit C++20 können wir auf erweiterte Futures, Coroutinen, Transaktionen und noch mehr hoffen. Aus der Vogelperspektive betrachtet, sind die Concurrent-Features von C++11 und C++14 lediglich Implementierungsdetails, auf denen höhere Abstraktionen in C++17 und C++20 basieren. Hier ist die Serie zu all meinen Artikeln über die Concurrent Future in C++20.
Wie ich bereits geschrieben habe: In den Regeln geht es hauptsächlich um Threads, da weder GCC noch Clang oder MSVC die parallelen Algorithmen vollständig implementiert haben. Es ist nicht sinnvoll, Best Practices zu Features aufzustellen, die nicht verfügbar (parallele STL) oder noch gar nicht standardisiert sind.
Dies ist die erste Regel, dies es im Kopf zu behalten gilt. Die Regeln beschäftigen sich mit vorhandenen Multihreading-Features in C++11 und C++14. Die zweite Regel ist, dass Multithreading eine sehr anspruchsvolle Domäne ist. Das bedeutet, dass die Regeln Hilfen für die Anfänger und nicht die Experten in dieser Domäne anbieten. Die Regeln zum Speichermodell werden später folgen.
Jetzt geht es endlich los mit der ersten Regel.
CP.1: Assume that your code will run as part of a multi-threaded program
Ich war sehr erstaunt, als ich diese Regel zum ersten Mal las. Warum soll ich für den Spezialfall optimieren? Um es klar zu stellen: Diese Regel bezieht sich vor allem auf Bibliothek und nicht auf Applikationen. Die Erfahrung zeigt immer wieder, dass Bibliotheken häufig wiederverwendet werden. Das bedeutet natürlich, dass du für den allgemeinen Fall optimierst.
Um die Regel auf den Punkt zu bringen, folgt hier ein kleines Codebeispiel.
double cached_computation(double x)
{
static double cached_x = 0.0; // (1)
static double cached_result = COMPUTATION_OF_ZERO; // (2)
double result;
if (cached_x == x) // (1)
return cached_result; // (2)
result = computation(x);
cached_x = x; // (1)
cached_result = result; // (2)
return result;
}
Die Funktion cached_computation erfüllt zuverlässig ihre Aufgabe, wenn sie in einem Single-threaded-Programm ausgeführt wird. Das gilt aber nicht in einer Umgebung, in der mehrere Threads verwendet werden. In diesem Fall ist das Problem, dass die statischen Variablen cached_x (1) und cached_result (2) gleichzeitig gelesen und verändert werden. Der C++11-Standard erweiterte statische Variablen mit Blockgültigkeit zwar um Multithreading-Semantik, dies gilt aber nur für ihre Initialisierung: Statische Variablen mit Blockgültigkeit werden thread-sicher initialisiert.
Das ist praktisch, hilft aber nicht in dem konkreten Fall. Wird die Funktion cached_computation von mehreren Thread gleichzeitig aufgerufen, besitzt das Programm ein Data Race. Der Begriff Data Race ist sehr wichtig in Multithre-ding Programmen in C++. Daher will ich gerne genauer darauf eingehen.
Ein Data Race ist eine Konstellation, in der zumindest zwei Threads auf eine geteilte Variable zugreifen. Zumindest ein Thread versucht sie dabei zu modifizieren. Der Rest ist schnell erklärt. Hat ein Programm ein Data Race, besitzt es undefiniertes Verhalten (undefined behaviour). Undefiniertes Verhalten bedeutet, dass jede weitere Analyse des Programms hinfällig ist und das Programm alle möglichen Ergebnisse produzieren kann. Ich meine wirklich alle. In meinen Seminaren sage ich gerne: Falls das Programm undefiniertes Verhalten besitzt, hat es Cache-Fire-Semantik. Selbst der Computer kann in Rauch aufgehen.
Falls du die Definition eines Data Race genau studierst, wird dir auffallen, dass ein veränderlicher, geteilter Zustand notwendig für eine Data Race ist. Hier kommt einen kleine Tabelle um diese Beobachtung auf den Punkt zu bringen.

Was können wir tun, um das Data Race zu beseitigen? Die statischen Variablen variables cached_x (1) und cached_result (2) als konstant zu erklären, ist nicht zielführend. Das heißt natürlich im Umkehrschluss, beide Variablen sollten nicht geteilt werden. Hier sind ein paar Möglichkeiten, dies zu erreichen.
- Schütze beide statischen Variablen mit einem eigenen Lock.
- Verwende ein Lock, um den ganzen kritischen Bereich zu schützen.
- Schütze den Aufruf der Funktion function cached_computation durch ein Lock.
- Mache beide statischen Variablen zu thread-lokalen Variablen. Thread-lokal sichert zu, dass jeder Thread seine eigene Kopie der Variablen cached_x und cached_result besitzt. Analog zu einer statischen Variable, die an die Lebenszeit des main-Thread gebunden ist, die die Lebenszeit einer thread-lokalen Variable an die Lebenszeit ihres Threads gebunden.
Hier sind die Variationen 1, 2, 3 und 4.
std::mutex m_x;
std::mutex m_result;
double cached_computation(double x){ // (1)
static double cached_x = 0.0;
static double cached_result = COMPUTATION_OF_ZERO;
double result;
{
std::scoped_lock(m_x, m_result);
if (cached_x == x) return cached_result;
}
result = computation(x);
{
std::lock_guard<std::mutex> lck(m_x);
cached_x = x;
}
{
std::lock_guard<std::mutex> lck(m_result);
cached_result = result;
}
return result;
}
std::mutex m;
double cached_computation(double x){ // (2)
static double cached_x = 0.0;
static double cached_result = COMPUTATION_OF_ZERO;
double result;
{
std::lock_guard<std::mutex> lck(m);
if (cached_x == x) return cached_result;
result = computation(x);
cached_x = x;
cached_result = result;
}
return result;
}
std::mutex cachedComputationMutex; // (3)
{
std::lock_guard<std::mutex> lck(cachedComputationMutex);
auto cached = cached_computation(3.33);
}
double cached_computation(double x){ // (4)
thread_local double cached_x = 0.0;
thread_local double cached_result = COMPUTATION_OF_ZERO;
double result;
if (cached_x == x) return cached_result;
result = computation(x);
cached_x = x;
cached_result = result;
return result;
}
Zuerst einmal gilt, dass statische Variablen thread-sicher initialisiert werden. Daher muss deren Initialisierung in dem Programmschnipsel nicht geschützt werden.
- Diese Version ist ein wenig trickreich, denn ich muss insbesondere beide Locks in einem atomaren Schritt anfordern. C++17 bietet dafür den std::scoped_lock an. Dieser kann eine beliebige Anzahl von Locks in einem atomaren Schritt locken. In C++11 bietet sich eine std::unique_lock in Kombination mit der Funktion std::lock an. Meine Artikel Locks statt Mutexen bietet weitere Details zu Locks in C++11 und C++14. Diese Lösung besitzt eine Race Condition zwischen cached_x and cached_result, da auf beiden Variablen gleichzeitig zugegriffen werden muss.
- Die Version 2 verwendet eine gröbere Strategie. Normalerweise solltest du kein grob-granulares Locken anwenden, aber ich denke, in diesem Anwendungsfall ist es OK.
- Dieser Ansatz ist mit Abstand der grob-granularste, denn die ganze Funktion wird gelockt. Klar, der Nachteil dieser Option ist es, dass der Anwender der Funktion für die Synchronisation des Funktionsaufrufs verantwortlich ist. Das ist, allgemein gesprochen, eine sehr schlechte Idee.
- Erkläre einfach deine statischen Variablen als thread-lokal und schon ist das Problem gelöst.
Am Ende hängt die Frage, welche Option gewählt wird, von deren Performanz und den Anwendern ab. Daher solltest du jede Version testen, ihre Performanz messen und dir Gedanken zu den Programmierern machen, die die Funktion anwenden und weiterpflegen.
Wie geht's weiter?
Dieser Artikel war lediglich der Startpunkt zu einer längeren Reise durch die Regeln zu Concurrency in C++. Im nächsten Artikel werde ich über Threads und geteilten Zustand schreiben.
Weitere Informationen:
Für meine drei offenen Seminare im zweiten Halbjahr 2018 sind noch Plätze frei. Die Schulungen finden im Großraum Stuttgart statt.
- Embedded-Programmierung mit modernem C++: 10.07 - 12.07 (Termingarantie)
- C++11 und C++14: 11.09 - 13.09
- Multithreading mit modernem C++: 13.11 - 14.11
Unter www.ModernesCpp.de sind die Details zu den drei Schulungen.
Ich freue mich immer darauf, mein Wissen vermitteln zu dürfen. ()
