

Nvidia Ampere GA100: GPU-Vollausbau mit 8192 Kernen
Nvidias größter Ampere-Chip fasst im Vollausbau bis zu 8192 Rechenkerne. Für Supercomputer kommt die abgespeckte A100-Version mit knapp 7000 Kernen zum Einsatz.

Neuer Ampere-Grafikchip von Nvidia
(Bild: Nvidia)
Nvidia hat zur jüngst enthüllten GPU-Generation Ampere weitere technische Informationen veröffentlicht. So fasst die neu entwickelte GA100-Grafikeinheit im Vollausbau sogar bis zu 8192 FP32-Rechenkerne, von Nvidia auch Cuda Cores genannt, und halb so viel Double-Precision-fähige Kerne.
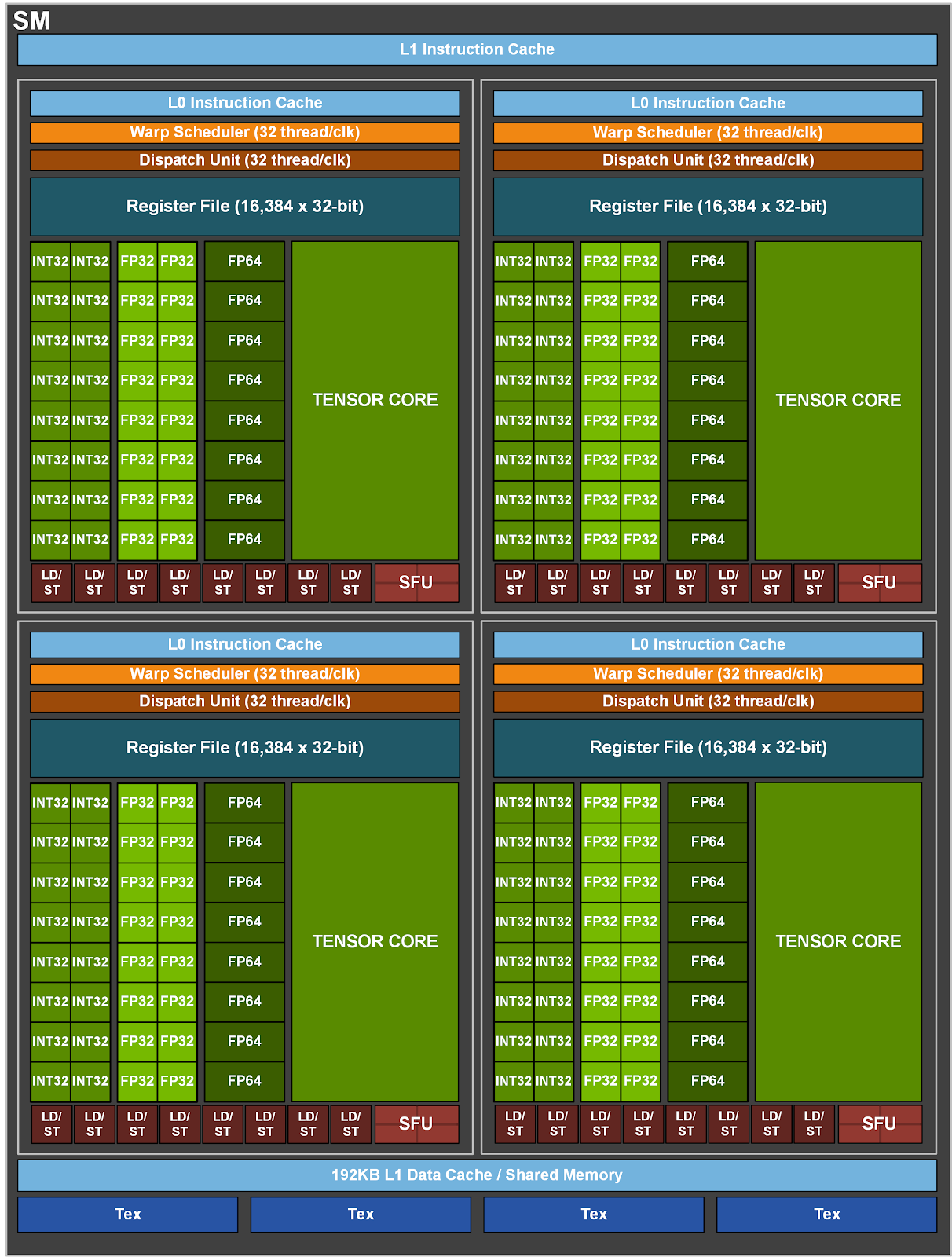
(Bild: Nvidia)
Auf dem kürzlich vorgestellten A100-Modul (SXM4) für Supercomputer sitzt eine leicht abgespeckte Fassung mit "nur" 6912 Kernen, die mit 1410 MHz Turbo-Taktfrequenz laufen (GPU Boost Clock). Im Vergleich enthält der GA100-Vollausbau 128 statt 108 Shader-Multiprozessoren, von denen jeder 64 FP32- und 32 FP64-Kerne trägt sowie vier Tensor Cores der dritten Generation.
Fast 1,9 TByte/s
Letztere unterstützen erstmals Berechnungen mit doppelter Genauigkeit, das neue TensorFloat32-Format und können Sparse Matrix Operations doppelt so schnell verarbeiten. Jeder Shader-Multiprozessor verarbeitet bis zu 64 Warps und entsprechend 2048 Threads. Sechs HBM2-Stacks mit insgesamt 48 GByte Speicher werden im Vollausbau über insgesamt 6144 Datenleitungen angebunden und können bei einer Taktfrequenz von 1215 MHz eine Transferrate von 1,87 TByte pro Sekunde erreichen. Beim A100 sinds dagegen 40 GByte Speicher mit knapp 1,6 TByte/s.
Empfohlener redaktioneller Inhalt
Mit Ihrer Zustimmung wird hier ein externes Video (TargetVideo GmbH) geladen.
Ich bin damit einverstanden, dass mir externe Inhalte angezeigt werden. Damit können personenbezogene Daten an Drittplattformen (TargetVideo GmbH) übermittelt werden. Mehr dazu in unserer Datenschutzerklärung.
Im Vergleich zum HPC-Vorgänger Volta stehen jedem Shader-Multiprozessor 192 KByte statt 128 KByte an kombiniertem L1-Cache und Shared Memory zur Verfügung. Über einen neuen Asynchronous-Copy-Befehl lassen sich Daten aus dem globalen Speicher unter Umgehung des L1-Caches direkt ins Shared Memory laden ohne auf Zwischenregister zugreifen zu müssen. Der außerhalb der Graphics Processing Cluster liegende L2-Cache fasst 40 MByte – also mehr als 6 Mal so viel wie noch bei der V100-GPU. Das soll in Verbindung mit einer neuen L2-Datenkompression laut Nvidia für eine Leistungssteigerung bei aufwendigen HPC- und KI-Berechnungen sorgen.
Weitere technische Informationen fasst Nvidia in einem Blogbeitrag zusammen.

(Bild: Nvidia)
A100 für Supercomputer
Ob Nvidia Produkte mit dem GA100 im Vollausbau plant, ist derzeit völlig unklar. Für Supercomputer und Rechenzentren verkauft Nvidia den leicht abgespeckten A100. Erste Abnehmer sind das Jülich Supercomputer Centre, das Rechenzentrum Garching der Max-Planck-Gesellschaft, das Karlsruhe Institute of Technology, das U.S. Department of Energy’s National Energy Research Scientific Computing Center im Lawrence Berkeley National Laboratory und die Indiana University. Außerdem bietet Nvidia als erstes Ampere-System den Deep-Learning-Server DGX-A100mit acht A100-GPUs zum Preis von knapp 200.000 US-Dollar an.
(mfi)
