

Programmiersprachen-Benchmark: Julia liest Daten viel schneller als Python und R
Beim jüngsten Release von Julia stand Performance im Fokus, und in einem Benchmark hat der CSV-Parser der Sprache besonders gut abgeschnitten.

(Bild: alphaspirit/Shutterstock.com)
- Silke Hahn
Bei einem Performancevergleich von in der Statistik häufig genutzten Programmiersprachen schnitt offenbar Julia beim Lesen von Daten in unterschiedlichen Szenarien und in der Gesamtwertung am besten ab. Der vom Julia-Team durchgeführte Benchmark-Test hat die Programmiersprachen anhand ihrer Parser für das Auslesen von CSV-Daten (Comma-separated Values) geprüft. CSV ist eines der gebräuchlichsten Formate zum Austausch strukturierter Daten.
Videos by heise
Drei CSV-Parser im Performance-Vergleich
In Workflows der Datenanalyse steht das Laden ausgelesener Daten typischerweise am Anfang, für die Datenanalyse eingesetzte Programmiersprachen sollten es entsprechend rasch und unterbrechungsfrei bewerkstelligen. Im aktuellen Vergleich wurden die drei hinsichtlich Performance jeweils als Klassenbeste geltenden CSV-Parser der Programmiersprachen Julia, Python und R auf die Probe gestellt: fread (R), read_csv (von Pandas, einer Datenanalyse-Library aus dem Python-Ökosystem) und CSV.jl (Julia).
Die Parser von Python und R sind in C geschrieben und über Wrapper in ihre Programmiersprachen eingebunden, wohingegen CSV.jl vollständig in nativem Code in Julia implementiert ist. Dieses Alleinstellungsmerkmal dürfte Julia hinsichtlich der Performance einen Vorteil verschafft haben. Im Gegensatz zum Pandas-Parser ermöglicht CSV.jl und fread das Multithreading beim Laden von CSV-Daten.
Big Data: Datengrundlage und Ergebnisse des Vergleichs
Acht unterschiedliche Datensätze aus realen, frei zugänglichen Big-Data-Sammlungen wie Apples Börsenkursen, Hypothekenrisiken oder den Ankäufen einer Kreditanstalt lagen dem Test zugrunde. Die Komplexität der zu verarbeitenden Daten nahm über die Testreihe hinweg zu, von homogenen Datensätzen mit derselben Datenart in allen Spalten bis hin zu heterogenen Datensätzen mit gemischten Spalten. Die einzelnen Datensätze umfassten bis zu mehreren Millionen Zeilen und teils über 2000 Spalten. Zum Benchmarking waren für Julia BenchmarkTools.jl, für R microbenchmark und für Python timeit im Einsatz.
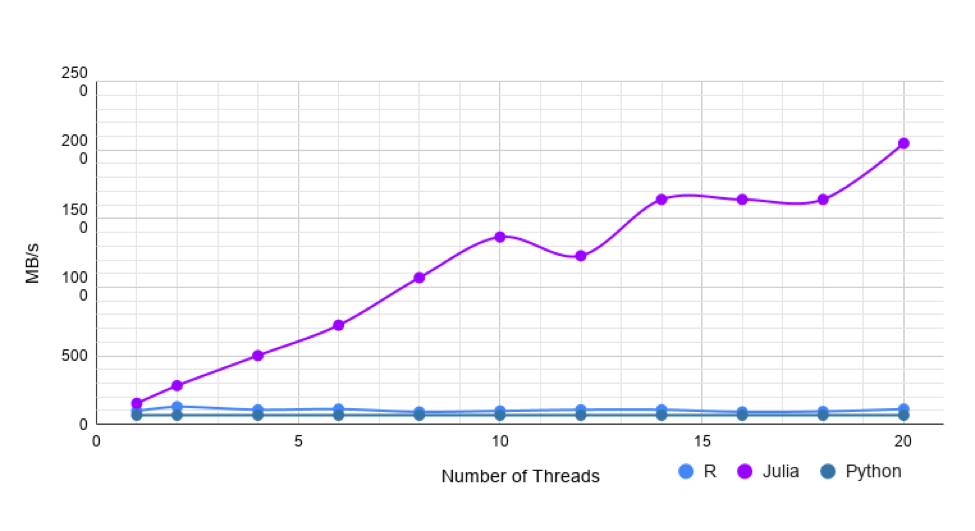
(Bild: Juliacomputing.com)
Julias CSV-Parser erwies sich als anderthalb- bis fünfmal so schnell wie der von Pandas, wenn der Test auf einem einzigen Core ablief. Mit aktiviertem Multithreading hängte Julia Python noch deutlicher ab und war genauso schnell oder schneller als der Parser von R. Julia beherrscht seit Version 1.3 das Multithreading. Die aktuelle Version ist 1.4, bei der Performance im Vordergrund steht.
Die detaillierten Ergebnisse des Performance-Vergleichs lassen sich im Blogeintrag von Julia Computing einsehen. Dort stehen auch die Diagramme der absolvierten Testreihen zur Verfügung und die zugrunde liegenden Datensätze lassen sich aufrufen.
(sih)
