

Big Data: Pinterest veröffentlicht quelloffene Web-IDE zur Datenabfrage
Querybook bietet eine Notebook-Oberfläche zum Durchführen und Visualisieren von Abfragen über Big-Data-Query-Engines wie Hive, Presto und SparkSQL.

(Bild: whiteMocca/Shutterstock.com)
Der Betreiber der Online-Pinnwand Pinterest hat mit Querybook ein Open-Source-Tool zur Abfrage von Daten über Query-Engines aus dem Big-Data-Umfeld veröffentlicht. Die IDE bietet ein interaktives Notebook-Interface und ermöglicht das Teilen der Dokumente. Die Abfragen laufen asynchron im Hintergrund, während das Tool regelmäßig die Ergebnisse aktualisiert.
Querybook startete laut der Ankündigung 2017 als internes Projekt und ist seit März 2018 im internen Einsatz. Im Schnitt kommt das Tool wohl täglich auf 500 aktive Nutzerinnen und Nutzer (DAU, Daily Active Users), und es soll zu den am besten bewerteten internen Werkzeugen gehören.
Datendokumente im Notebookformat
Im Vordergrund zeigt ein Web-UI die Inhalte in einem Notebook-Interface, das interaktiv aufgebaut ist und an Jupyter Notebooks erinnert. Die einzelnen Dokumente, die DataDocs heißen, enthalten Zellen mit Queries, Texten und Charts. Sie lassen sich im Team mit anderen teilen und parallel in Echtzeit bearbeiten.
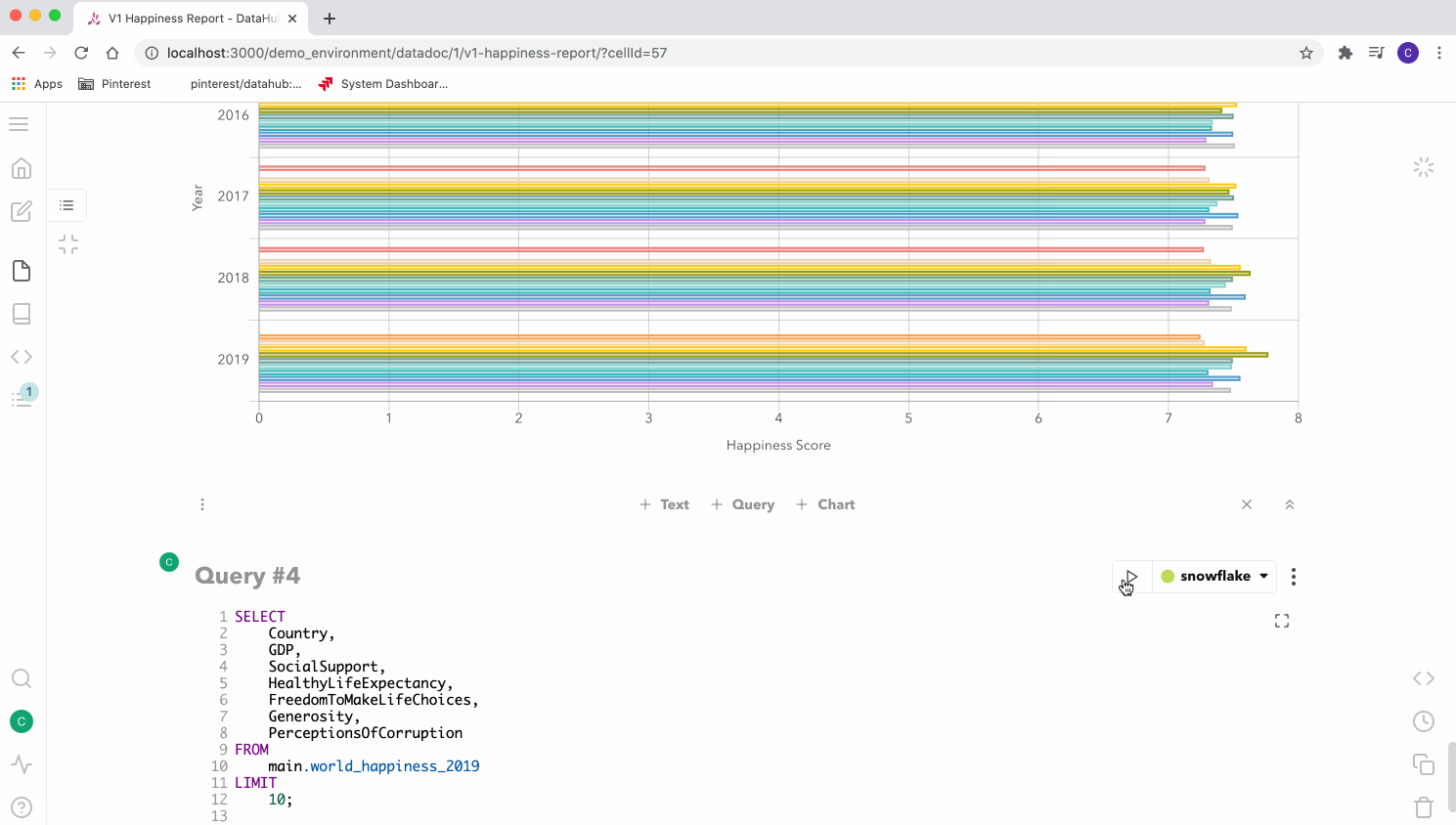
(Bild: Pinterest)
Query-Zellen sind die zentrale Anlaufstelle zum Durchführen der Abfragen. Der Editor bietet Autovervollständigung und Syntaxhervorhebung anhand der im Dokument verwendeten Tabellen und deren Spalten. Für die Visualisierung bietet das Tool zahlreiche der üblichen Chart-Typen wie Balken-, Kreis- oder Streudiagramme.
Die Abfrageergebnisse lassen sich zudem für Python oder als Google Sheets exportieren, und für langwierige Abfrage ist eine Benachrichtigung über E-Mail oder Slack vorgesehen.
Hinter der Bühne
Im Hintergrund erfolgen die Abfragen nicht direkt auf die Query-Engines. Die Weboberfläche greift auf einen Webserver zu, der einen Query-Task erzeugt und über Redis an einen Worker übergibt. Dieser kommuniziert schließlich mit Hive, SparkSQL, Presto oder einer anderen Abfrage-Engine und aktualisiert die Ergebnisse regelmäßig, während die Query läuft.

(Bild: Pinterest)
Nach dem Abschluss legt der Worker die Abfrage entweder in einer lokalen Datei beziehungsweise Datenbank oder einem externen Storage-System wie AWS S3 (Simple Cloud Storage) oder Google Cloud Storage ab. Abschließend gibt der Webserver das Ergebnis an die Weboberfläche zurück. Querybook aktualisiert zudem die Inhalte der DataDocs regelmäßig in einer Elasticsearch-Instanz, um Suchen innerhalb der Dokumente zu ermöglichen. Querybook analysiert alle Queries, um Metadaten wie referenzierte Tabellen zu ermitteln und damit die Datenschemata und das Ranking für die Suche anzupassen.
Erweiterung für Open Source
Auf dem Weg zur Offenlegung des Projekts für den externen Gebrauch hat Pinterest das Tool um eine Admin-Oberfläche und ein Plug-in-System ergänzt, um zum einen die Verwaltung zu vereinfachen und zum anderen Schnittstellen zu anderen Systemen als die intern genutzten zu ermöglichen. Bei den Query-Engines bietet das Tool eine Anbindung an Presto, Hive, Druid, Snowflake, Big Query, MySQL, Sqlite, PostgreSQL, SQL Server und Oracle.
Weitere Details lassen sich der Ankündigung von Querybook entnehmen. Der Code ist unter Apache-2-Lizenz auf GitHub verfügbar. Zusätzliche Informationen finden sich auf der Projektseite.
(rme)
