

Data Science: Apache Hop Orchestration Platform 1.0 kommt ohne Code aus
Der Kettle-Fork Hop soll es Datenexperten ermöglichen, ohne Code rein visuell zu arbeiten und mit Metadaten zu beschreiben, wie Daten zu verarbeiten sind.

(Bild: gopixa/Shutterstock.com)
- Silke Hahn
Die quelloffene Apache Hop Orchestration Platform (kurz Hop) ist in der ersten Hauptversion erschienen. Seit September 2020 befindet sich das 2019 begonnene Projekt bei der Apache Foundation in der Inkubationsphase. Data Scientists und Entwicklerinnen können damit Workflows und Pipelines in einer visuellen Entwicklungsumgebung auf Windows, macOS und Linux erstellen und bearbeiten. Ergänzend gibt es auch eine Browserversion (Hop Web). Mit dem Ensemble aus portierbaren Runtimes, Projekten und Umgebungen sowie integrierter Versionskontrolle, Testingmöglichkeiten und weiteren Funktionen sollen Teams den gesamten Lebenszyklus ihrer Projekte mittels Hop steuern und verwalten können.
Visuell first, Code second (oder ganz entbehrlich)
Wer mit Hop arbeitet, benötigt nach Angaben der Projektbetreiber wenig bis keine Programmierkenntnisse, denn alle Arbeiten wie das Entwerfen, Ausführen, Prüfen, Debuggen und Betreiben von Daten-Workflows und -Pipelines soll rein visuell möglich sein. Laut Ankündigung im Apache-Blog sind alle Funktionen über das Hop GUI (Grafische Nutzeroberfläche) greifbar, wobei programmiererfahrene Entwicklerinnen und Entwickler alternativ auch mit Befehlszeilen arbeiten können.

(Bild: Apache Foundation)
Videos by heise
Minimalistische Engine für IoT-Geräte und Datenstreaming
Hop ist ein Fork der Plattform für Datenintegration Kettle (Pentaho Data Integration in Version 8.2.0.7), doch nach Auskunft der Herausgeber soll es "kein feindlicher Fork" sein, sondern als komplementäres Projekt die Möglichkeiten der Datenintegration experimentell vorantreiben. Durch die Trennung der beiden Projekte gibt es laut Projektverantwortlichen nun eine klare Aufteilung in eine stabile Plattform (Kettle) und die neue Spielwiese zum Ausprobieren von Ideen und Neuerungen (Hop).
Was Hop wesentlich von Kettle unterscheidet, ist die Reduktion auf einen Kern von Grundfunktionen, alles andere hat das Team aus der Engine-Architektur in den Plug-in-Bereich ausgelagert. Ziel ist laut Blogeintrag auf der Apache-Projektseite, dass Hop Daten von IoT-Geräten im PetaByte-Bereich für das Streaming, Batching oder hybride Datenszenarien verarbeiten kann.

Im Zuge der Abspaltung von Kettle blieb dabei laut Herausgebern "kein Stein auf dem anderen": So hat Hop sämtliche Abhängigkeiten aktualisiert, Teile der Codebasis entfernt oder umgeschrieben und die Hop-Engine umgebaut. Insgesamt liegt der Schwerpunkt auf einem modularen Plug-in-Konzept, so unterstützt die Engine über 400 Plug-ins und insgesamt 20 verschiedene Plug-in-Typen.
Strikte Trennung zwischen Metadaten und Konfiguration
Eine weitere Besonderheit neben der Betonung einer schlanken Engine mit Plug-ins liegt auf der Unterstützung verschiedener Einsatzszenarien. Über das Hop GUI oder wahlweise auch das Kommandozeilenwerkzeug hop-conf können Anwenderinnen und Anwender für jedes ihrer Projekte die passende Umgebung festlegen, je nach Einsatzzweck wie Entwicklung, Testing oder CI/CD (Continuous Integration/Continuous Delivery beziehungsweise Deployment). Zwischen diesen Umgebungen ist einfaches Wechseln über ein Drop-down-Menü in der grafischen Oberfläche möglich. Hop trennt strikt den Code in den Metadaten eines Projekts von der Konfigurationsebene (den Dateien der Arbeitsumgebung).

(Bild: Apache Foundation)
Portierbare Runtime für beliebiges Deployment
Wer mit Hop als Data Engineer oder Datenentwickler Workflows und Pipelines entwirft, kann sie laut Projektteam an beliebigen Orten bereitstellen. Neben der lokalen und nativen Engine laufen die im GUI erstellten Pipelines ebenfalls auf Apache Spark, Apache Flink, Google Dataflow oder Apache Beam.
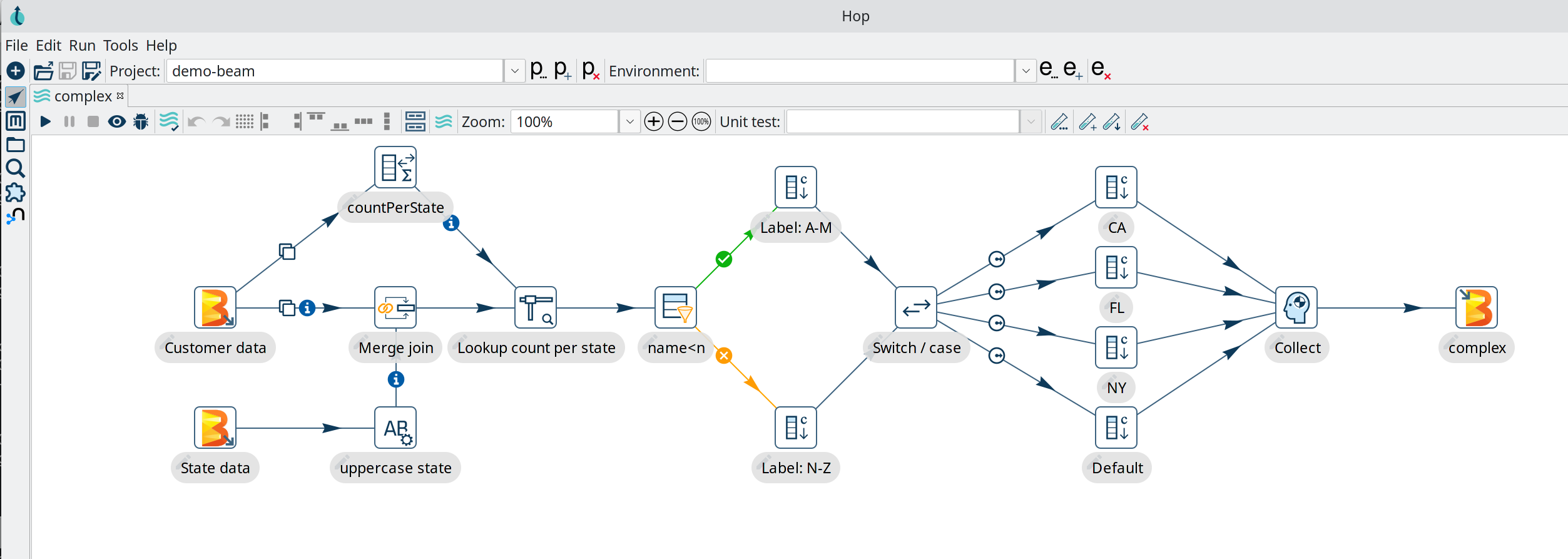
(Bild: Apache Foundation)
Auch Unit-Tests zum Prüfen von Workflows und Pipelines lassen sich in der Hop GUI einbinden. Sie können auch mit komplexeren Integrations- oder Regressionstests kombiniert werden, um sicherzustellen, dass ein gesamtes Projekt oder System sich so verhält wie erwartet. Die Orchestrierungsplattform umfasst eine stetig wachsende Bibliothek an Unit-, Regressions- und Integrationstests, mit denen unter anderem auch die Hop-Entwickler selbst nach eigenen Angaben tiefliegende Probleme der Kettle-Codebasis feststellen und beheben konnten.
Roadmap: Da kommt noch was
Was geplant ist, verrät ein Blick in die aktuelle Version der Roadmap: Das Hop-Projekt plant die Einrichtung eines Software-Marktplatzes für Plug-ins von Drittanbietern, plugbare Field Expressions im Bereich Transformationen und Aktionen, die Integration mit Apache Airflow (sowohl in Airflow selbst als auch in einer neuen Workflow-Engine). Eine Modularisierung der Apache-Beam-Plug-ins ist vorgesehen samt weiteren Vereinheitlichungen der Beam-Plug-ins, und die laufende Konvertierung aller Plug-ins zur generischen XML-Serialisierung soll es Entwicklern künftig ermöglichen, JSON-, YAML- und ähnliche Metadaten für Pipelines und Workflows zu serialisieren.
Offenbar arbeitet das Hop-Team auch an einer neuen grafischen Benutzeroberfläche (GUI) zum Ausführen, für die Vorschau und das Debugging von Pipelines und Workflows. Geplant ist wohl auch ein Networking-Dienst zum Überwachen und Protokollieren, der in der Lage sein soll, Metadaten aus dem laufenden Betrieb lokaler und entfernter Hop-Ausführungen anzunehmen.
Ressourcen und weiterführende Hinweise
Wer sich genauer für die aktuellen und geplanten Neuerungen bei Apache Hop interessiert, mag einen Blick in den ausführlichen Blogeintrag zum Release der ersten Hauptversion werfen. Weitere Ressourcen stehen in der Dokumentation bereit, in der Anwender und Entwickler jeweils eigene Leitfäden finden. Hinweise zur Architektur und ein Q&A-Bereich sowie eine Einführung für die ersten Schritte mit der Plattform runden das Informationspaket auf der Hop-Projekt-Website bei Apache ab. Auch die Downloadmöglichkeiten sind dort aufgeführt.
(sih)