

Nvidias GF100: 512 Shader-Kerne und 64 Textureinheiten
Nvidia hat einige Details des bereits lange erwarteten GF100-Grafikchips veröffentlicht, der allerdings nicht vor Mitte März erscheinen dürfte.
Während AMD seit September 2009 bereits über 2 Millionen zu DirectX 11 kompatible Grafikchips abgesetzt hat, sind Nvidias GeForce-Konkurrenzkarten mit GF100-Grafikchips noch immer nicht erhältlich. Zumindest die neuentwickelte Architektur der zukünftigen Tesla-Rechenkarten hat Nvidia bereits zu deren Ankündigung im vergangenen Jahr erläutert. Nun gab die kalifornische Firma am Rande der CES in Las Vegas einige Details zu den ab Mitte März erwarteten GeForce-Grafikkarten mit DirectX-11-Unterstützung preis, verschwieg jedoch die finalen Taktfrequenzen, machte keine Angaben zur Leistungsaufnahme und zeigte auch keine aussagekräftigen Vergleichsbenchmarks.
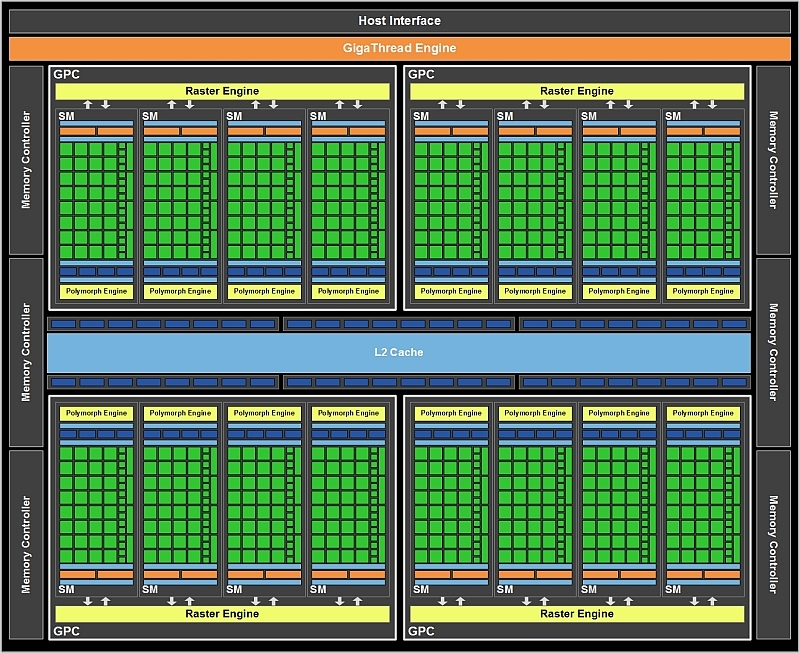
(Bild: Nvidia)
Der GF100-Grafikchip besteht im Vollausbau aus insgesamt vier sogenannten Graphics Processing Clusters (GPC), die jeweils über eine eigene Raster-Engine verfügen und vier Streaming Multiprocessors (SM) enthalten. Die insgesamt 16 SMs besitzen jeweils einen 64 KByte großen konfigurierbaren Zwischenspeicher (Shared Memory/L1) und teilen sich einen 768 KByte fassenden, vereinheitlichten L2-Cache (Read/Write) sowie sechs 64-Bit-Speicherkanäle. Der Grafikchip ist dadurch über 384 Datenleitungen an den GDDR5-Speicher angebunden. Zum Vergleich: AMD koppelt GDDR5-Speicher und Grafikchip auf der Radeon HD 5870 mit 256 Leitungen. Hinsichtlich der verfügbaren Speicherbandbreite liegt Nvidia hier zumindest vorn.
Jede SM beherbergt 32 Shader-Einheiten, die Nvidia als CUDA-Kerne bezeichnet. Insgesamt besitzt der GF100-Chip, zumindest im höchsten Ausbau, also 512 solcher Kerne – der aktuelle GT200b-Chip kommt auf maximal 240 Einheiten. 16 Load/Store-Einheiten sorgen pro SM für den Transfer der Daten zwischen den Rechenkernen und den Zwischenspeichern.

(Bild: Nvidia)
An jedem der 16 SMs ist ein Cluster aus vier Textureinheiten (TMUs) angedockt, die nun effizienter arbeiten sollen und unter anderem auch spezielle DirectX-11-Texturkompressionsformate und Gather4-Operationen unterstützen. Insgesamt verfügt der GF100 also über lediglich 64 TMUs. Dies scheint für einen Chip, mit dem Nvidia die Leistungskrone beanspruchen will, zu wenig, besaß doch bereits der GT200b einer GeForce GTX 285 gleich 80 TMUs. Der Knackpunkt scheint hierbei jedoch die Taktfrequenz zu sein. Liefen die 80 TMUs einer GeForce GTX 285 mit nur 648 MHz („Graphics Clock“, wie auch die Rasterendstufen/ROPs), will Nvidia die Textureinheiten beim GF100 mit einer deutlich höheren Taktfrequenz ansteuern. Unbestätigten Gerüchten zufolge sollen die Textureinheiten gar so flott wie die Shader-Rechenkerne laufen („Hotclock“), was ihre geringe Anzahl mehr als kompensieren würde. Diese Taktfrequenz betrug beim GT200b 1476 MHz (GeForce GTX 285), beim GF100 dürfte sie sich ebenfalls in ähnlichen Regionen bewegen.
Die unter anderem für die Kantenglättung (Antialiasing/AA) wichtigen ROPs dürften jedoch weiterhin mit der langsameren "Graphics Clock" laufen, im GF100-Grafikchip sind davon 48 vorhanden (GeForce GTX 285: 32, Radeon HD 5870: 32), unterteilt in insgesamt 6 ROP-Partitionen. Die Kantenglättungsleistung will Nvidia deutlich verbessert haben, besonders beim achtfachen Antialiasing soll die Bildrate nicht mehr so drastisch einbrechen wie noch beim GT200b-Chip. So sei der GF100 um bis zu den Faktor 2,3 schneller als der GT200b einer GeForce GTX 285. Zudem unterstützt die GF100-GPU nun auch 32x Coverage Sampling Antialiasing, bei dem acht Farb- und 24 Coverage-Samples zur Kantenglättung genutzt werden, und bietet zudem verbessertes Transparency Multisampling.

(Bild: Nvidia)

(Bild: Nvidia)
Um den Anforderungen von DirectX 11 gerecht zu werden, müssen Grafikchips Tessellation unterstützen, durch das sich geometrische Details von Polygonmodellen verfeinern lassen. Beim GF100-Chip beinhaltet jeder Streaming Multiprocessor eine eigene Tessellation-Engine (PolyMorph Engine). Laut Nvidia bearbeiten die 16 Tessellation-Engines geometrische Daten parallel, dadurch soll die Tessellation-Leistung der GF100-GPU bis zu sechsmal höher sein als die des RV870-Chips der AMD-Konkurrenzkarte Radeon HD 5870. Diese Behauptungen fußen jedoch auf speziell für den GF100-Chip selektierten Geometrie-Benchmarks. Wie hoch die tatsächliche Spieleleistung der GF100-Grafikkarte im Vergleich zu den derzeitigen AMD-Spitzenmodellen sein wird, steht weiterhin in den Sternen.
Auch wann die ersten GF100-Karten in den Handel kommen sollen, ist noch immer unklar. Brancheninsider gehen jedoch nicht von einem Marktstart vor Mitte März aus. Zumindest die Anfang März in Hannover stattfindende IT-Messe Cebit dürfte Nvidia nutzen, um die finalen Spezifikationen der GF100-Grafikkarten zu veröffentlichen. Bis dahin hat Konkurrent AMD seine DirectX-11-Serie von HD-5000-Karten bereits komplettiert. (mfi)
