

Linux 4.19: Schöner starten und bereit für das WLAN von Morgen
Seite 4: Storage: bessere Datenträger-Regulierung und SMB-Snapshot-Support
Ressourcenverbrauch von Datenträgern anders regulieren
Mit dem neuen I/O-Controller "Blk-Iolatency" sollen Admins besser sicherstellen können, dass Datenträgerzugriffe weniger wichtiger Software (etwa die Systemaktualisierung) die kritischeren Server-Anwendungen nicht zu stark verlangsamen. Der neue Mechanismus soll sogar vor Situationen bewahren können, in denen vernachlässigbare Aufgaben die Systemlast so hoch treiben, dass sich das System komplett festfährt.
Das Ganze soll mit minimalen I/O-Latenzen gelingen, die Admins über den neuen I/O-Controller für Control Croups (Cgroup) festlegen können. Fortan behält der Kernel ein Auge auf die Lese- und Schreibanforderungen des Systems und ermittelt den Durchschnitt der I/O-Operationen, den Programme der mit Cgroups definierten Prozessgruppen erzielen. Sollte dieser Wert den konfigurierten übersteigen, drosselt der Kernel die Operationen von Programmen, die in Cgroups mit weniger hohen Latenzanforderungen stecken; dadurch sollen Ressourcen frei werden, damit die wichtigeren Anwendungen nach Möglichkeit wieder innerhalb der gesetzten Latenz zum Zuge kommen. Notfalls beendet der Controller weniger wichtige Anwendungen sogar, um die Vorgaben zu erreichen. Das Ganze klappt sogar bei indirekt entstehenden Datenträgeroperationen – beispielsweise, wenn eine weniger wichtige Anwendung viel Arbeitsspeicher fordert und das System so verlangsamt, weil es Arbeitsspeicher auslagern muss (Swapping).

(Bild: git.kernel.org – d70675121546 )
Der Ansatz stammt von Facebook-Mitarbeitern. Ihnen zufolge hat sich der Controller in den Rechenzentren des Social-Media-Dienstes bewährt, wo er Abstürze verhindert, Schwankungen in der Antwortzeit reduziert und die Zahl der pro Sekunde erfüllten Aufgaben gesteigert hat. Details zum Ansatz liefert ein LWN.net-Artikel; weitere Hintergründe und Hinweise zum praktischen Einsatz liefern die Dokumentation zum neuen Controller und Commits wie blkcg: add generic throttling mechanism, block: introduce blk-iolatency io controller und block: make iolatency avg_lat exponentially decay.
Snapshots von SMB-Freigaben einhängen
Das zum Einbinden von Samba- oder Windows-Freigaben genutzte CIFS bietet jetzt Snaphot-Unterstützung. In Kombination mit einer neuen Version der Werkzeugsammlung Cifs-Utils lassen sich so mit dem Mount-Parameter "snapshots=" ältere Dateisystemstände schreibgeschützt mounten, sofern der Server solche denn exportiert; aktuelle Samba-Versionen beherrscht das via vfs_shadow_copy2.
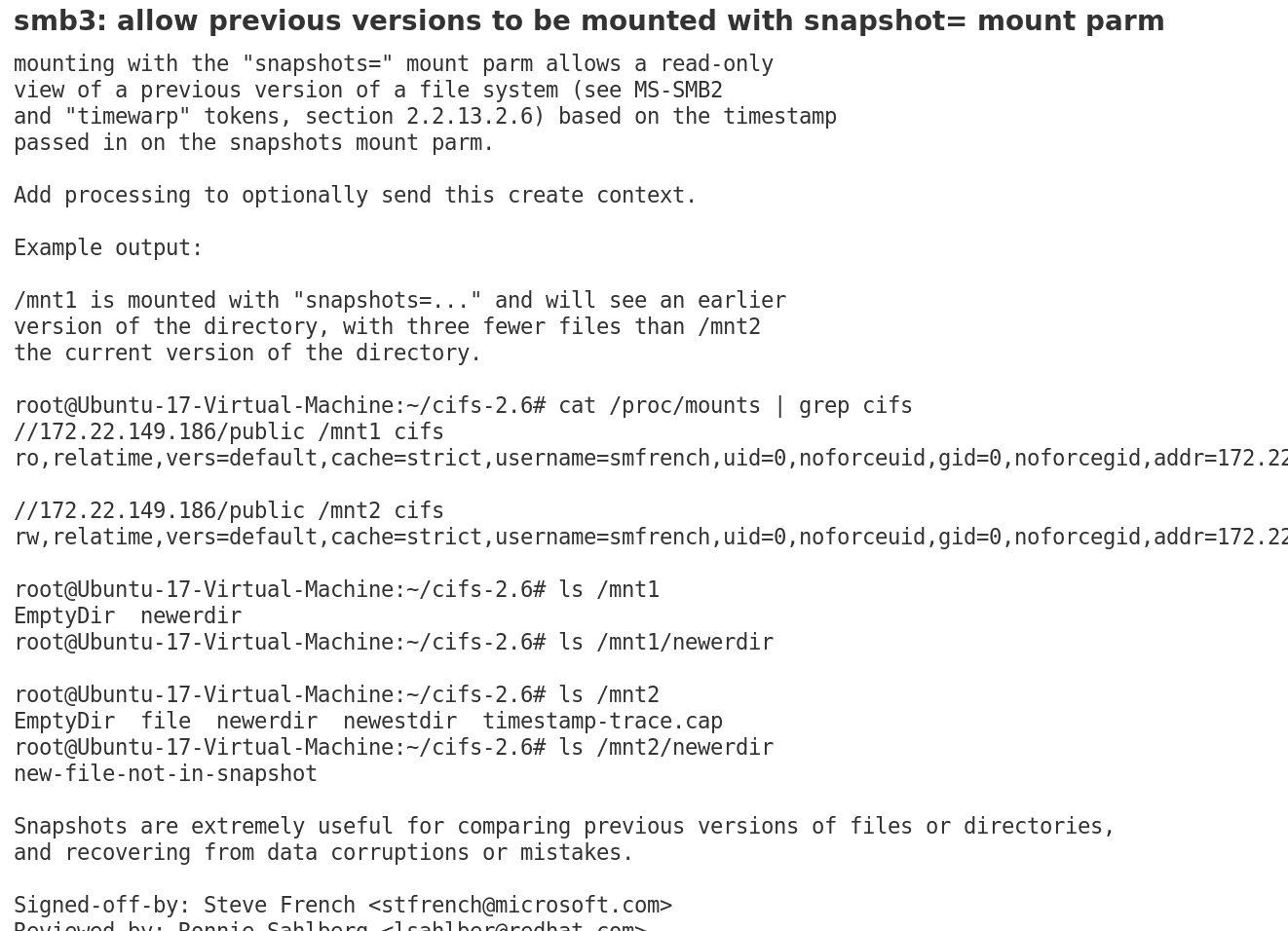
(Bild: git.kernel.org – cdeaf9d04a5a )
Unter den weiteren Änderungen an CIFS waren welche, die ein Bündeln mehrere Anfragen (Compounding) verbessern, was die Abfrage von Dateieigenschaften (Name, Größe, Attribute, …) per statfs() um 40 Prozent verbessern soll. Außerdem lässt sich der CIFS-Support jetzt auch so übersetzen, dass er veraltete und bekanntermaßen unsichere Protokollstandards wie CIFS/SMB 1.0 nicht mehr unterstützt.
Zweiter Versuch: Multiqueue-Support für AHCI & Co.
Beim Erstellen einer neuen Konfiguration zum Bau eines Linux-Kernels wird der Multiqueue-Support im SCSI-Subsystem jetzt standardmäßig aktiviert; das hat auch Auswirkungen auf SATA-Treiber wie AHCI, die auf dem SCSI-Support aufbauen. Durch den Multiqueue-Support können solche Treiber die modernere Infrastruktur des Block-Layers nutzen, die mit mehreren Warteschlangen arbeitet. Dieser Multi-Queue Block IO Queueing Mechanism (Blk-Mq) wurde vor einigen Jahren geschaffen, um das Leistungspotenzial der damals schnellsten PCIe-SSDs ausschöpfen zu können. Aber auch SSDs und Festplatten für Desktop-PCs, Notebooks oder einfache Server können von der moderneren Infrastruktur profitieren; zudem funktionieren modernere Storage-I/O-Scheduler wie das bei Linux 4.12 integrierte BFQ (Budget Fair Queueing) nur mit Datenträgern, bei denen der Treiber die Multiqueue-Unterstützung des Block-Layers nutzt.
Bereits vor rund einem Jahr hatten die Kernel-Entwickler versucht, den Multiqueue-Support im SCSI-Subsystem standardmäßig zu aktivieren. Bei einigen Nutzern führte das aber zu Problemen beim Wechsel in oder aus dem Bereitschaftsmodus (Suspend/Resume); außerdem traten eine Reihe von Performance-Probleme zutage. Die Entwickler haben die Änderungen daher rückgängig gemacht und sind die Schwierigkeiten angegangen, um jetzt einen zweiten Anlauf zu wagen.
Zweiter Versuch: Weiteres API zur Abfrage asynchroner I/O-Operationen
Zu Abfragen des Fortschritts bei Asynchronen I/O (AIO) steht jetzt das neue Polling-Interface IOCB_CMD_POLL bereit. Die verwendete Programmierschnittstelle wurde von einem API abgeleitet, das Red Hat Advanced Server (RHAS) 2.1 und Red Hat Enterprise Linux (RHEL) 3 bereits vor knapp fünfzehn Jahren genutzt haben. Das neue API zur Abfrage entstand im Auftrag von Scylla, deren Entwickler es offenbar bei ihrer NoSQL-Datenbank verwenden wollen. Das bei LWN.net näher erläuterte Interface war vor zwei Monaten bereits für Linux 4.18 integriert worden, flog aber wieder raus, nachdem Torvalds einige problematische Eigenschaften fand; der Programmierer der Erweiterung hat daraufhin einen neuen und noch dazu kompakteren Ansatz entwickelt.
Btrfs, Ext4 & XFS
Unter den wichtigsten Änderungen an Btrfs war eine, durch die sich nun prinzipiell beschreibbare Dateien defragmentieren lassen, solange Anwendungen diese gerade nur lesend geöffnet haben.
Die Ext4-Entwickler planen schon für das nächste Jahrhundert: Sie haben ein für Inode-Zeitstempel verwendetes Datenfeld vergrößert, das sonst im Jahr 2106 an seine Grenze gelangen und überlaufen würde. Zwischen dem Hauptschwung an Ext4-Änderungen stecken zudem zahlreiche Patches, die bislang im Wiki des Dateisystems gepflegte Hintergrundinformationen in die Kernel-Dokumentation überführen; Letzte enthält dadurch jetzt einen umfangreichen und tiefen Einblick in Design und Funktionsweise des Dateisystems.
Unter den wichtigsten Änderungen an XFS (1, 2) waren neben Optimierungen einige weitere Funktionen, um XFS-Dateisysteme zukünftig im Betrieb prüfen und reparieren zu können.
Neues Nur-Lesen-Dateisystem und Aufräumarbeiten
Linux bringt jetzt auch Support für das Enhanced Read-Only File System (EROFS) mit (u.a. Kconfig-Update, Todo-Datei, On-disk layout). Laut den Entwicklern ist es ein leichtgewichtiges Nur-Lesen-Dateisystem, das etwa für Live-CDs oder den Firmware-Speicher von Mobilgeräten gedacht ist. Der von Huawei eingebrachte Dateisystemcode erfüllt allerdings die Qualitätsstandards der Kernel-Entwickler nicht. Er landete daher im Staging-Bereich, der für Code gedacht ist, den jemand im Rahmen der normalen Kernel-Entwicklungsprozesse auf Vordermann gebracht werden soll. Diese Hoffnung geht immer mal wieder nicht auf. Dann fliegt der Code sang- und klanglos wieder raus, denn beim Staging-Bereich gelten Sonderregeln, die das explizit erlauben. Mit anderen Funktionen des Kernels (Dateisystemen, Treibern, …) passiert das nicht, solange Anwender sich darauf verlassen: Das wäre eine Regression, gegen die Linus Torvalds strikt vorgeht, wenn er davon hört.
Über den Modul-Parameter metacopy=on kann man das Overlay-Dateisystem (OVL) jetzt anweisen, sich das Hochkopieren von Dateiinhalten in die oberste Dateisystemschicht zu sparen, wenn lediglich Dateiattribute mit Programmen wie chown oder chmod verändert werden. Das Überlagerungsdateisystem kann mit der standardmäßig inaktive Funktion so Overhead vermeiden, was die Performance verbessert.
Zwischen den Änderungen am Block Layer war auch ein Patch, der Unterstützung für asynchrone Zugriffe auf SCSI-Geräte via BSG-Interface entfernt: Dieser Zugriffsweg weist bekannte Schwachstellen auf und wird offenbar ohnehin von niemandem verwendet, wie ein LWN.net-Artikel zum Thema erläutert.
Einige weitere Änderungen rund um Storage-Support nennen die Commit-Kommentare der wichtigsten Merges bei den Subsystemen ATA, Ceph, Device Mapper (DM), MD, MTD, Libnvdimm (MISC, Memory Failure) und SCSI.
Die wesentlichen Neuerungen bei bislang nicht genannten Kernel-Dateisystemen finden sich in wichtigsten Merge-Commits der Subsysteme F2FS, GFS2, NFS, NFSd, OVL aka OverlayFS und UBI/UBIFS.
