Make-loses Java mit der z2-Environment
Seite 2: Pull-Deployment
Ziehen statt drücken
Wesentliches Merkmal des Pull-Deployment-Ansatzes ist, dass das Deployment-Ziel, etwa die Laufzeitumgebung, erkennt, welche Änderungen seit einem vorherigen Pull aufgetreten sind und wie darauf zu reagieren ist, um wieder ein konsistentes Abbild der zugrunde liegenden Quellen zu erstellen. Dadurch ergeben sich signifikante Vorteile: Änderungen anderer Entwickler werden erkannt und konsistent angewendet – auf allen beteiligten Installationen der Laufzeitumgebung, sodass sich Änderungen im Team ständig integrieren lassen.
Hingegen können beim Push-Deployment-Ansatz durch die inkonsistente Integration schnell nicht triviale Probleme entstehen, was dazu führen kann, dass Entwickler die zügige Integration mit der Arbeit anderer durch "Eingraben" auf Zwischenstände vermeiden.
Das Problem liegt in den Projektabhängigkeiten: In der Regel bestehen Applikationen und schon gar komplexere Anwendungsszenarien, hier Lösungen genannt, nicht aus unabhängigen Entwicklungsprojekten: Implementierungen und Datentypen werden über die Grenzen von Entwicklungsprojekten und Deployables hinweg wiederverwendet.
Zum Beispiel kann die Änderung einer einzelnen Klasse den erneuten Make und ein erneutes Deployment mehrerer Deployables erfordern, um wieder eine konsistente, dem aktuellen Stand entsprechende Ausführungsumgebung zu erhalten. Da die Verwendungsbeziehung schnell weitverzweigte Graphen bildet, ist das Erkennen aller notwendigen Aktualisierungen nicht einfach, jedoch vom Entwickler zu gewährleisten.
Verteilte Welt
Nicht nur die Produktion, auch die Entwicklung betreibt Anwendungen hochgradig verteilt. Seltenere Vorgänge wie die Installation eines lokalen Applikationsservers mit einem initialen Entwicklungsstand oder zum produktiven Betrieb können daher zu oft unerwartetem Aufwand führen. Das liegt einerseits daran, dass viele Entwickler oft ähnliche, aber doch nicht identische Konfigurationen benötigen, oder daran, dass Softwarestände unterschiedliche Versionsanforderungen an die Ausführungsumgebung haben. Ein Grund mag zudem sein, dass in einem Skalierungsszenario auch kleinere Aktualisierungen manuelle Schritte auf jedem eingebundenen Rechner erfordern.
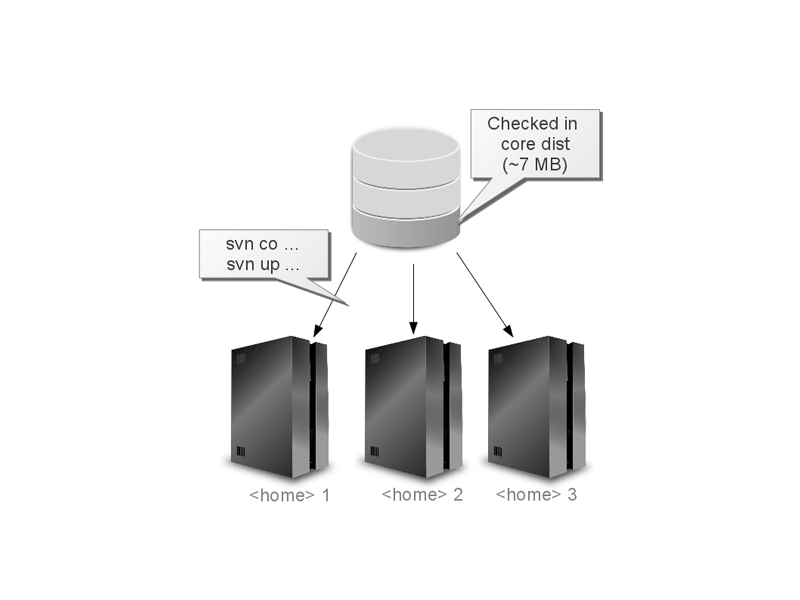
Da die z2-Environment einen relativ kleinen und selten anzupassenden Kern hat, ist es praktikabel, ihn neben den Entwicklungsprojekten in die Quellverwaltung einzuchecken. Das reduziert die Installation und die Ausskalierung eines gegebenen Lösungssystems auf das Check-out oder Update einer Versionsverwaltung. Zusammen mit dem Pull-Deployment-Ansatz sind Aktualisierungen damit weitgehend unabhängig von der Komplexität der eigentlichen Modifikation und erfordern stattdessen stets nur die Auslösung einer Synchronisation (oder eine Aktualisierung des Kerns).