

Parallelprogrammierung mit Clojure
Seite 2: Unveränderliche Daten und Datenstrukturen
Unveränderliche Daten
Ein wesentlicher Bestandteil von Clojures Concurrency-Maschinerie sind die Datenstrukturen, etwa Vektore und (Hash-)Maps. Für das schlüssige Gesamtbild der Sprache sind zwei Eigenschaften der Datenstrukturen von großer Bedeutung. Zum einen lassen sich die gespeicherten Informationen nicht mehr verändern, zum anderen ist die Implementierung hinreichend geschickt, dass zu großer Overhead beim Kopieren vermieden wird.
Datentypen in Clojure enthalten Werte, und Werte sind unveränderlich. Alle Daten in Clojure sind somit unveränderlich (immutable). Diese Feststellung ist von zentraler Bedeutung. Wenn ein Programm einer Liste einen Wert hinzufügen will, muss es eine neue Liste anlegen, in der alle alten Werte und der neue Wert enthalten sind. Wenn ein Programm zu einer zuvor gemerkten Zahl einen weiteren Wert addieren will, wird die Addition eine neue Zahl zurückliefern. Eine Zuweisung der Form x = x + 2 ist für Clojures Datentypen nicht vorgesehen; für veränderliche Daten existieren spezielle Referenztypen.
Persistente Datenstrukturen
In den meisten Fällen bedeutet "Persistieren" das Speichern von Daten auf einen nichtflüchtigen Datenträger, meist eine Festplatte. Eine "persistente Datenstruktur" hingegen hat mit Persistenz im Sinn des Erhalts der Werte auch nach einem Stromausfall nichts zu tun, sondern bezeichnet das beobachtete Verhalten, dass nach einer Manipulation der Datenstruktur die vorherige Version ebenfalls noch vorhanden ist (siehe auch den Blog-Eintrag "Grokking Functional Data Structures" von Debasish Ghosh). In dem Sinn sind Clojures persistente Datenstrukturen nichtflüchtig. Die von Sprachen wie Java oder C bekannten Datenstrukturen hingegen, die eine direkte Manipulation erlauben, sind flüchtig: Nach einer Manipulation ist die vorherige Version nicht mehr erreichbar.
Clojures Datenstrukturen sind unveränderlich, das Hinzufügen eines Werts zu einer Liste von Werten erzeugt eine neue Datenstruktur. In einer naiven Umsetzung, die eine neue Datenstruktur durch eine vollständige Kopie erzeugt, könnte das viel Speicher benötigen und die Performance spürbar negativ beeinflussen. Clojure begegnet der Herausforderung mit einer effizienten Organisation persistenter Datenstrukturen, bei der sich die Datenstrukturen die im Speicher vorgehaltenen Werte teilen ("Shared Structure"). Fügt man einem Vektor mit zehn Werten einen weiteren Wert hinzu, entsteht ein Vektor, der Verknüpfungen zu den ersten zehn Werten enthält und zusätzlich noch eine weitere Verknüpfung zum neuen Wert.
Die wichtige Voraussetzung dafür ist, dass die gemeinsam verwendeten Daten sich nicht verändern können.
Organisation in Bäumen
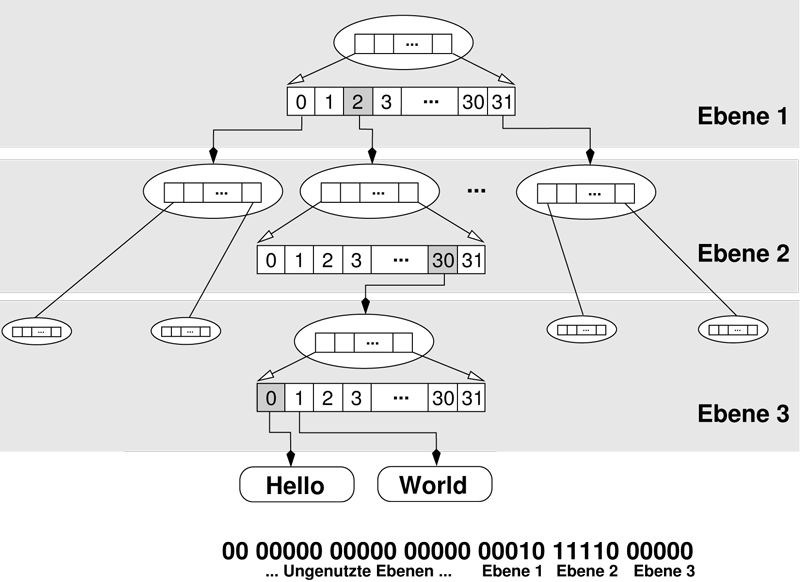
Die Organisation der Dateninhalte übernehmen flache Baum-Strukturen, die aus bis zu fünf Ebenen bestehen. In der ersten Ebene befindet sich der Root-Knoten des Baums, und der Knoten hat Platz für 32 Objekte. Diese sind, solange die Datenstruktur nur bis zu 32 Objekte aufnehmen muss, die zu speichernden Dateninhalte. Beim Einfügen des 33. Werts wird eine neue Ebene im Baum erzeugt. Dann enthält der Root-Knoten nicht mehr 32 Verweise auf Dateninhalte, sondern auf 32 neue Knoten, die ihrerseits die zu speichernden Objekte enthalten. In dieser Ebene ist Platz für bis zu 32 x 32 = 1024 Objekte. Fügt man ein weiteres hinzu, entsteht wieder eine neue Ebene, die dann Platz für bis zu 32^3 = 32768 Objekte bietet.
Wird auf ein Objekt in dieser Datenstruktur mit seinem Index zugegriffen, muss Clojure im Baum den korrekten Pfad zum Objekt finden. Dazu nutzt die Sprache die Eigenschaft von Java, Integerwerte in 32 Bit zu speichern. Diese 32 Bit werden in sechs Gruppen zu je fünf Bit zerlegt, und jede Gruppe ist für den Index innerhalb einer Ebene des Baums zuständig. Die fünf Bits kodieren genau die benötigten 32 Werte für den Index in einem Knoten.
Auf die Weise kann Clojure bis zu 32^6 = 2^{30} Werte in einer Datenstruktur speichern und einen Zugriff auf persistente Datenstrukturen innerhalb von O(log_{32} N) garantieren.
Die Abbildung 1 zeigt den Zugriff auf den Index 3008, in binärer Schreibweise: 00 0000 00000 000000 00010 11110 00000. Die tatsächliche Implementierung enthält kleinere Abweichungen von dem Prinzip, die der Verbesserung der Performance dienen.
Unterschiedliche Referenztypen im Einsatz
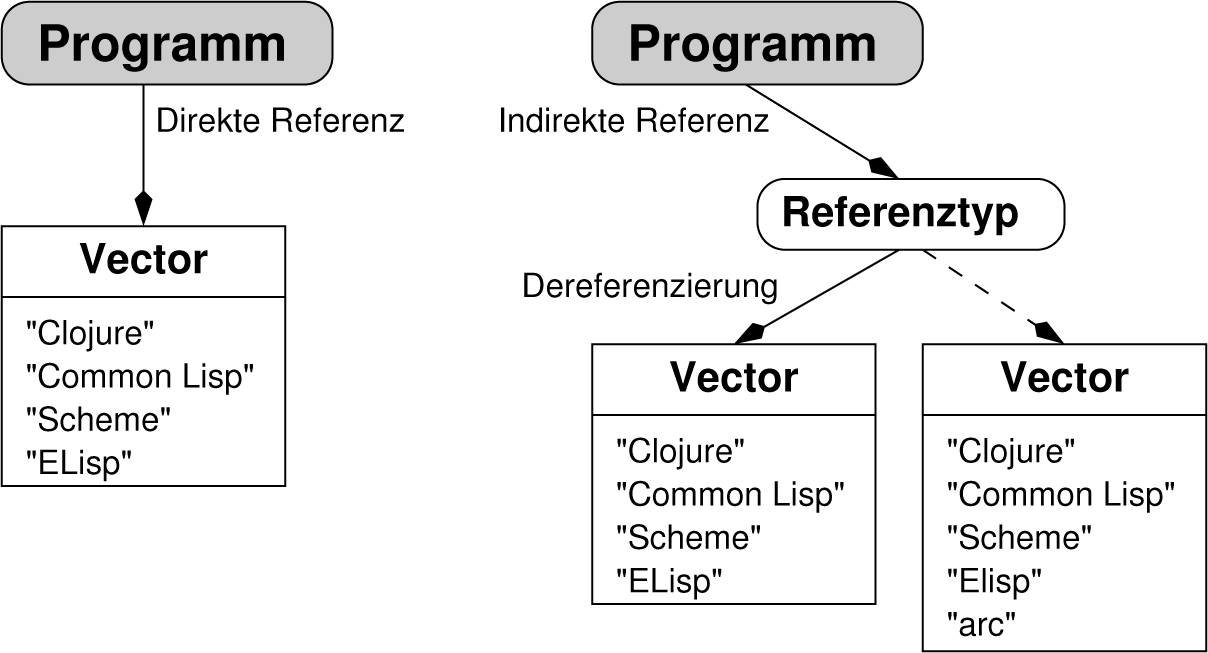
Clojure verwendet für die Modellierung der Zeit außerhalb des eigenen Threads unterschiedliche Referenztypen. Im Unterschied zu Sprachen wie Java und C hält das Programm jedoch keine direkten
Referenzen auf Werte, sondern indirekte. Sie erlauben einen deutlich einfacheren Zugriff. Hierdurch hält das Programm keine direkte Referenz auf den Datenblock mehr, sondern auf ein Objekt, das davor sitzt. Benötigt ein Programmteil den Wert, muss es die gehaltene Referenz dereferenzieren. Will man aber die gespeicherten Daten verändern, lässt sich im Hintergrund und für andere Programmteile unsichtbar die neue Datenstruktur aufbauen, bis schließlich die Referenz in einem einzigen Schritt, atomar, umgehängt wird. Die Manipulation etwa eines Vektors ist ein aufwendigerer Prozess. Das gilt nicht nur für zusammengesetzte Datenstrukturen; schon das Verändern des primitiven Datentyps long in Java ist nicht unbedingt ein atomarer Vorgang. Die Abbildung 2 verdeutlicht den Unterschied zwischen direkter und indirekter Referenz und zeigt, wie eine indirekte auf eine neue Datenstruktur verweist.
Clojure implementiert vier Referenztypen mit unterschiedlichen Eigenschaften, die sich damit für unterschiedliche Anwendungsfälle empfehlen:
- Var
- Atom
- Ref
- Agent
Vars finden Verwendung für Daten, deren Änderungen nur lokal in einem Thread sichtbar sein sollen. Ihre Manipulation verlangt somit keinen Aufwand für eine Synchronisierung zwischen Threads. Im Gegensatz zu den anderen Referenztypen erfolgt der Zugriff auf die referenzierten Inhalten ohne ausdrückliches Dereferenzieren.
Atoms koordinieren Thread-übergreifend Lesen und Schreiben eines einzelnen Werts. Änderungen sind in anderen Threads sichtbar. Zum Zugriff auf den Wert wird das Atom dereferenziert.
Refs verhalten sich weitgehend so wie Atoms. Allerdings erlaubt Clojure durch Einsatz von Software Transactional Memory (STM) die konsistente Manipulation mehrerer Refs.
Agents arbeiten asynchron und seriell, wodurch die Fehlerbehandlung aufwendiger wird. Auch bei ihnen erfolgt der Zugriff durch Dereferenzieren.
