

GTC 2012: Die GK110-Schöpfer über Performance und zukünftige Herausforderungen
Nvidias Kepler-Entwickler Jonah Alben und John Danskin über die Performance von GK110, dessen Entwicklung und Herausforderungen bei der GPU-Entwicklung.

(Bild: Martin Fischer)
Im Rahmen der GPU Technology Conference hatten wir die Gelegenheit, mit den Nvidia-Experten Jonah Alben und John Danskin ein Gespräch zu führen. Sie waren maßgeblich an der Entwicklung der Kepler-GPUs beteiligt. Alben ist der zuständige Senior Vice President für den Bereich GPU Engineering und Danskin Vice President für die GPU-Architektur.
c't: Wieviel schneller wird GK110 im Vergleich zum GK104 in der Praxis sein?
Alben: Wir haben die genauen Produkspezifikationen, etwa die endgültigen Taktfrequenzen, noch nicht veröffentlicht. Es kommt natürlich auf das jeweilige Programm an – die Frage ist also: limitiert die Anzahl der Funktionseinheiten oder das Speicherinterface? Limitiert letzteres, kann man wahrscheinlich mit einem Geschwindigkeitsgewinn von rund 50 Prozent rechnen. Rechenintensive Programme wie SGEMM dürften dagegen ganz gut mit der Zahl der Einheiten skalieren.
c't: Also könnte man auf einen durchschnittlichen Geschwindigkeitsvorteil zwischen 50 und 70 Prozent schließen?
Alben: Das oder etwas mehr könnte man sich für gewöhnliche Programme erhoffen. Für HPC-Anwendungen, die Gebrauch von den neuen Funktionen Hyper-Q und Dynamic Parallelism machen oder Double-Precision-Berechnungen ausführen, sollte es aber deutlich mehr sein.
c't: Wie lange war Kepler in Entwicklung?
Alben: Das kommt ganz darauf an, wen man fragt. Ich habe beispielsweise gleich nach der Fertigstellung des G80-Chips angefangen, am Kepler-Projekt zu arbeiten, das war vor zirka sieben Jahren. Erst vor rund drei Jahren waren dann richtig viele Nvidia-Mitarbeiter in verschiedenen Teams involviert.

(Bild: Nvidia)
c't: Wieso kommt GK110 erst Ende des Jahres, also so viel später als GK104?
Danskin: Schneller ging es einfach nicht. GK104 hat weniger Funktionen als GK110 und ist primär ein Grafik- und kein Compute-Chip; er musste zur richtigen Zeit am Markt erscheinen. Außerdem ist GK110 eine wirklich große GPU – da spielt auch das Tape-Out und die Fertigung bei TSMC eine Rolle.
Alben: Es wäre unmöglich gewesen, einen so großen Chip gleichzeitig mit einer neuen Fertigungstechnik einzuführen. Der 28-Nanometer-Prozess musste zunächst noch etwas reifen.
c't: Was war die größte Herausforderung bei der Entwicklung von GK110?
Alben: Ganz klar die Implementation der neuen Funktionen Hyper-Q und Dynamic Parallelism.
Danskin: Besonders kompliziert war tatsächlich Dynamic Parallelism, durch das die GPU selbstständig neue Kernel erzeugen kann. Hyper-Q hat zwar einige Leute beschäftigt, war aber viel einfacher zu implementieren und führt nur zu mehr Performance. Dynamic Parallelism ermöglicht es dagegen Programme zu schreiben, die vorher in der Form unmöglich waren. Für uns war das das Feature mit der größten Bedeutung.
(Bild: Nvidia)
c't: Setzt Nvidia bei GK110 auf dedizierte Double-Precision-Einheiten oder arbeiten dafür mehrere Single-Precision-Kerne zusammen?
Danksin: Es gibt eigenständige Double-Precision-Einheiten.
c't: Nehmen diese viel Platz in Anspruch?
Alben: Zumindest nicht wenig. Dadurch belegt eine GK110-SMX deutlich mehr Die-Fläche als jene von GK104. Ein weiterer Platzfresser ist die Implementation der ECC-Funktionen.
c't: GK110 hat ein Double- zu Single-Precision-Verhältnis von 1:3 – wieso nicht 1:2?
Danskin: Das wäre architekturbedingt schwierig umzusetzen.
Alben: Es kostet schlicht mehr Ressourcen: wir bräuchten mehr Register und müssten die Transferraten und andere Dinge ändern.
Danskin: Wahrscheinlich wäre dann auch die Performance pro Watt beziehungsweise pro Millimeter geringer. Das jetzige Verhältnis passt einfach gut.
c't: Warum hat sich Nvidia bei GK110 für ein 384-Bit statt 512-Bit-Speicherinterface entschieden?
Danskin: Ein 512-Bit-Interface würde die Leistungsaufnahme erhöhen und überdies ebenfalls Platz kosten. Was wiederum weniger Ausführungseinheiten auf dem Chip ermöglicht hätte. GK110 mit 384 Bit bietet die bessere Balance.
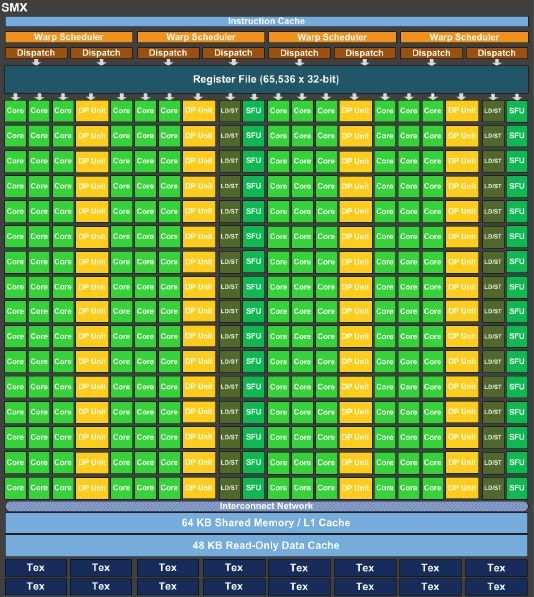
(Bild: Nvidia)
c't: Auf der Tesla K20 will Nvidia eine GK110-GPU mit 13 oder 14 SMX-Rechenblöcken einsetzen. Wird es in absehbarer Zeit auch eine Karte geben, auf der ein GK110-Chip im Vollausbau, also mit 15 SMX-Blöcken, arbeitet?
Alben: Irgendwann vielleicht.
c't: Wird der GK110 einen verbesserten Hardware-Video-Transcoder mitbringen?
Alben: GK110 wird den gleichen Hardware-Transcoder wie GK104 enthalten.
c't: Worin liegen die größten Herausforderungen bei der Entwicklung zukünftiger GPUs?
Danskin: Die größte Herausforderung bleibt die Leistungsaufnahme. Schaut man etwas in die Vergangenheit, haben wir und AMD bis zu einem bestimmten Punkt eine höhere Performance schlicht mit einer höheren Leistungsaufnahme erkauft. Das hat sich nun aber geändert, der Leistungsaufnahme sind klare Grenzen gesetzt. Auch jeweils feinere Fertigungstechniken helfen diesbezüglich nicht mehr in dem Maße wie in der Vergangenheit.
Alben: Es geht schlicht primär um die Performance pro Watt. Das Design eines Grafikchips muss sich diesem Faktor unterordnen. (mfi)
