

Benchmarking Spark: Wie sich unterschiedliche Hardware-Parameter auf Big-Data-Anwendungen auswirken
Dank leistungsfähiger Hadoop-Distributionen ist es einfach geworden, ein komplettes Hadoop/Spark-Cluster in der Cloud zu installieren. Schwieriger wird es jedoch, die optimale Konfiguration der virtualisierten Cloud-Hardware für den jeweiligen Anwendungsfall zu finden, denn unterschiedliche Hardwarekonfigurationen können sich sehr wohl auf das Verhalten von Spark-Anwendungen im Cluster-Betrieb auswirken.
- Ramon Wartala

Dank leistungsfähiger Hadoop-Distributionen ist es einfach geworden, ein komplettes Hadoop/Spark-Cluster in wenigen Stunden in der Cloud zu installieren. Schwieriger wird es jedoch, die optimale Konfiguration der virtualisierten Cloud-Hardware für den jeweiligen Anwendungsfall zu finden, denn unterschiedliche Hardwarekonfigurationen können sich sehr wohl auf das Verhalten von Spark-Anwendungen im Cluster-Betrieb auswirken.
Benchmark bezeichnet im Allgemeinen das Vermessen eines Systems. Dabei werden Mess- und Bewertungsverfahren gebildet, um die Qualität und die Leistungsfähigkeit des zu prüfenden Systems mit Kennzahlen beurteilen zu können. Wichtig dabei: Der Benchmark muss sich jederzeit wiederholen lassen, um objektive, valide und verlässliche Daten liefern zu können. Benchmarks informationsverarbeitender Systeme bestehen zumeist aus einzelnen oder Gruppen von Programmen, welche die Leistungsfähigkeit des Systems wiederholbar und übertragbar messen können.
Apache Hadoop wurde einer breiteren Öffentlichkeit bekannt, als es Yahoo 2008 damit gelang, den Terabyte Sort Benchmark zu gewinnen. Seit dieser Zeit sind weitere Hadoop-spezifische Benchmarks hinzugekommen, welche die unterschiedlichen Anforderungen an ein verteiltes System darstellen und vergleichbar machen sollen. Einer der vielseitigsten ist die Benchmark-Suite HiBench, die der Prozessorhersteller Intel als Referenz für die Messung von Hadoop- und Spark-Clustern unter der Apache-Lizenz zur Verfügung gestellt hat. In der aktuellen Version 4.0 werden zehn typische Workloads vermessen, die die Bandbreite aller möglichen Arten von Big-Data-Anwendungen abdecken sollen.
HiBench eignet sich gut dazu, die Leistung unterschiedlicher Cluster-Konfigurationen (Anzahl Nodes, CPU-Kerne, Netzwerk- und Storage-I/O etc.) miteinander zu vergleichen. Wer jedoch nur seine eigene Spark-Anwendung auf ihr Performanceverhalten in verschiedenen Cluster-Konfigurationen prüfen möchte, wird andere Lösungen finden müssen. Bevor auf das Vorgehen dabei eingegangen wird, sollen hier aber die wichtigsten Architekturbestandteile einer Spark-Anwendung zusammengefasst werden.
Architektur von Spark
Apache Spark ist ein Framework zur schnellen Analyse großer Datenmengen innerhalb eines Rechner-Clusters. Seine Stärken liegen dabei in der Nutzung des Hauptspeichers, um während der Verarbeitung schneller Zugriff auf Daten und Strukturen zu haben.
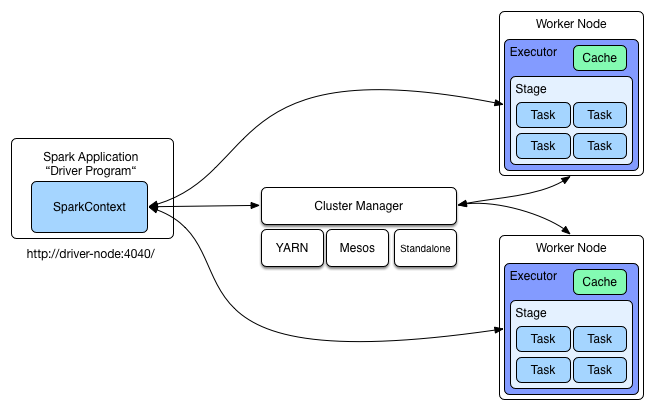
Ein Rechner-Cluster, auf dem Spark zur Ausführung kommt, besteht aus einer Menge einzelner Computersysteme, die über Netzwerkkomponenten verbunden sind. Das System lässt sich als Ansammlung von Ressourcen wie CPUs, Hauptspeicher, Festplatten und Netzwerkverbindungen betrachten. Das Verwalten der Ressourcen überlässt Spark der Cluster-Management-Software. Das Framework kann dabei sowohl allein als auch im Zusammenspiel mit YARN (Yet Another Resource Negotiator) oder Mesos betrieben werden.
Die Schnittstelle zwischen einer Spark-Anwendung und dem Cluster-Manager stellt der sogenannte SparkContext dar. Über ihn verteilt Spark sogenannte Executors auf die einzelnen Rechnersysteme im Cluster, um auf ihnen die Datenverarbeitung ausführen zu können.
Zur Messung der Leistungsfähigkeit eines Spark-Clusters ist es wichtig, die grundlegende Architektur und die Verarbeitung der Daten innerhalb des Spark-Systems zu verstehen. Ein kleiner Rundgang soll sowohl in die Termini als auch in die Besonderheiten der Spark-Architektur einführen.
Im Kern verwaltet und verarbeitet Spark seine Daten als sogenannte Resilient Distributed Datasets (RDDs). Diese verarbeiten Daten verteilt mithilfe zweier unterschiedlicher Arten von Operationen:
- Transformationen ermöglichen die Verarbeitung von Ausgangsdaten in Zieldaten zum Beispiel mit Filter- oder Gruppierungsfunktionen. Transformation liefern als Ergebnis immer ein RDD zurück. Bei Spark spricht man dabei oft von Parent RDDs, die einen Child RDD erzeugen. Transformationen lassen sich verketten. Als Ergebnis davon erzeugt Spark einen Directed Acyclic Graph (DAG), der zur Ausführungszeit abgearbeitet wird.
- Actions dagegen liefern nach ihrer Ausführung einen einzigen Ergebniswert zurück. Als Beispiel soll hier die Anzahl von Datenelementen stehen, die gezählt werden sollen (count).
Richtig schnell macht Spark dabei der Umstand, dass im Gegensatz zum Map-Reduce-Algorithmus von Hadoop die Daten nicht zwingend nach jedem Mapper- oder Reducer-Task auf eine Festplatte zwischenzuspeichern sind, sondern sich im Speicher des Clusters verteilen können. Deshalb spricht man von Spark auch als "In-Memory-Datenanalysesystem".
Das gilt jedoch nicht für alle Operationen, die Spark auf großen Datenmengen anwenden kann. Je nach Art und Umfang der zu verarbeitenden RDDs muss auch Spark die Daten auf dem lokalen System zwischenspeichern und gegebenenfalls über das Netzwerk auf einen anderen Knoten verschieben. Dieser als "shuffle" bezeichnete Zustand von Spark ist der große Zeitfresser beim Verarbeiten von Daten in RDDs.
