

Die Verknüpfung von Data Analytics und Supercomputing
Seite 3: Big Data und Supercomputer
Big Data und Supercomputing wachsen zusammen
Um den grundsätzlichen Problemen Datenmanagement, Analysegeschwindigkeit und Komplexität zu begegnen, arbeitet man an neuen Analytics-Ansätzen. Eine Möglichkeit ist die Kombination aus Supercomputing und Data Analytics in einer Hardware-Appliance mit HPC- und Big-Data-Software. Nutzern stehen dadurch einerseits die Rechengeschwindigkeit sowie Skalierungs- und Durchsatzraten eines Supercomputers und andererseits eine standardisierte Enterprise-Hardware sowie eine Open-Source-Softwareumgebung (etwa OpenStack für das Datenmanagement und Apache Mesos für die dynamische Konfiguration) zur Verfügung. Im Gegensatz zur oft zitierten "Schatten-IT", bei der unterschiedliche Cluster Architekturen jeweils für verschiedene Workloads eingesetzt werden und damit ein Problem für die Integration von Applikationen darstellt, wird mit diesem Modell auf die Verwendung einheitlicher und offener Quasi-Industriestandards gesetzt. Das ermöglicht die zeitgleiche Durchführung anspruchsvoller Analyse-Workloads – sei es Hadoop, Apache Spark oder Graph – auf einer einzigen Plattform.
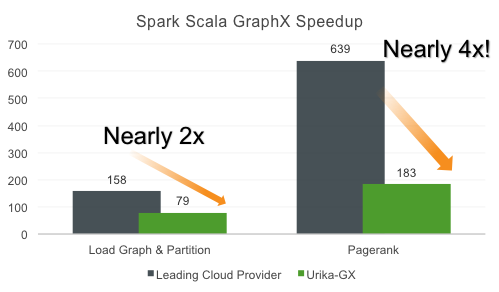
Bei einem Benchmark, bei dem die Performance von AWS EC2 mit jener der Cray Urika-GX Data Analytics Appliance verglichen wurde, lagen die Ergebnisse bei Graph-Workloads (Graph Load/Partitioning) bei der Urika-GX zwei- beziehungsweise viermal schneller vor (PDF). Der sogenannte LUBM25K-Graph-Benchmark zeigte sogar eine zwanzigfache Performancesteigerung gegenüber anderen Big-Data-Plattformen.
Anwendern im Enterprise-Bereich steht durch die Fusion von HPC-Technik und Open-Source-Software ein neues Instrument zur Verfügung, um schnell Einblicke in riesige Mengen unstrukturierter Daten zu bekommen.
HPC-Komponenten für Data Analytics
Ein wichtiges Element dieser Fusion ist im Fall von Cray der proprietäre Aries-Verbindungschip ("Aries Interconnect"), der auch in den Supercomputern eingesetzt wird. Dieses interne Netzwerk ist auf niedrige Latenz sowie hohe Bandbreiten ausgelegt und auf hohe Messaging-Raten ausgerichtet. Netzwerkabhängige Workloads wie Spark oder graphenbasierte Analysen laufen schneller, da sich die Datenpakete ständig einspeisen lassen ("in-flight"), ohne erst eine Rückmeldung abwarten zu müssen. Darunter versteht man die Fähigkeit des Netzwerks, große Mengen an Datenpaketen gleichzeitig auf dem Netz aktiv zu halten. Das ist eine Voraussetzung, um die sogenannte "einseitige" Kommunikation zu ermöglichen, bei der Sender nicht mehr auf eine Bestätigung der Empfänger warten, bevor sie das nächste Datenpaket verschicken, womit sich Kommunikationsströme überlappen lassen. Das drückt sich in hohen Raten an kleinen Datenpaketen auf dem Netz aus.
Zudem präsentiert der Aries-Chip den verteilten Hauptspeicher der einzelnen Rechnerknoten als einen globalen Adressraum und unterstützt sogenannte Atomic Memory Operations, mit denen sich nichtlokale Speicheradressen nutzen lassen. Der Aries-Verbindungschip (PDF) ersetzt Verbindungen per Ethernet- oder InfiniBand-Knoten, sodass die Notwendigkeit entfällt, eine Netzwerk-Fabrik zwischen einzelnen Knoten aufzubauen, die unnötig Zeit, Support und Kapital verschlingt.
Die Konvergenz von Supercomputing und Big Data in der Wissenschaft
Ein Projekt, das maßgeblich von der HPC-Big-Data-Konvergenz profitieren wird, ist das Human Brain Project des Jülich Supercomputing Centre und der Eidgenössischen Technischen Hochschule Lausanne. Hierbei handelt es sich um eine 10-Jahres-Initiative, die das gesamte Wissen über das menschliche Gehirn zusammenfassen und mittels computerbasierter Modelle und Simulationen die dort ablaufenden Prozesse nachbilden soll. Im Mittelpunkt des Projekts steht unter anderem die Entwicklung von Speicherlösungen, die auf die immensen Datenmengen ausgelegt sind, die im Zuge einer Hirnsimulation anfallen.
Auch die Argonne Leadership Computing Facility in den Vereinigten Staaten arbeitet mit datenzentrierten Anwendungen, zum Beispiel in den Bereichen Life Science, Materialwissenschaften und Machine Learning. Das Institut widmet sich der Erforschung und Optimierung verschiedener Rechenmethoden, welche die Grundlage für datengestützte Erkenntnisse in allen wissenschaftlichen Disziplinen bilden. Das Projekt Aurora hat zum Ziel, bis Ende 2018 eine neue, datenzentrische Supercomputer-Architektur zu entwickeln und zu installieren, die sich durch großen Gesamthauptspeicher und extreme Memory-Bandbreiten auszeichnet.
Ein weiterer Anwendungsfall ist die Analyse von Genomdaten und die Genomsequenzierung in der Krebsforschung, zum Beispiel beim Non-Profit-Forschungsinstitut Broad Institute in den Staaten, das sich um ein größeres Verständnis von Krankheiten und den Fortschritt bei deren Behandlung bemüht. In einem Benchmark-Test übertrug das Institut sein Genom-Analyse-Toolkit GATK4, das zuvor in der Cloud lief, eins zu eins auf die Urika-GX-Plattform und erhielt die Recalibration-(QSR-)Ergebnisse aus dem Analyse-Toolkit und der Spark-Pipeline mehr als viermal schneller als zuvor: in neun statt 40 Minuten (PDF).
